
NexusTrade · AI Agents from Scratch · Breaking Down the Claude Code Leak
Claude Code's source code just leaked. Today I'm going to teach you how it works.
Half a million lines of TypeScript. Most people reading it have no idea what they're looking at. This course fixes that.
 Austin Starks
✦ Founder, NexusTrade
✦ April 2026
✦ 8 min read
Austin Starks
✦ Founder, NexusTrade
✦ April 2026
✦ 8 min read
Why Now
Claude Code's source code just leaked. Half a million lines. And most people reading it have no idea what they're looking at.
On March 31, 2026, Anthropic accidentally published a source map in the Claude Code npm package that exposed the full TypeScript source. Over 512,000 lines. Gone public.
The internet went crazy.
Engineers are posting breakdowns. Developers are building clones. Everyone's asking the same question: how does this thing actually work?
If you already understood how AI agents are built, you'd know exactly what you're looking at.
That's the gap. And that's what this course closes.
"Building an AI agent isn't nearly as hard as you think."
I know this because I built one from scratch before most people knew the term. Ocebot was an autonomous claim adjudication agent I built at Oscar Health. It was running real healthcare workflows in production while the industry was still debating whether agents were real. Before that, I got a master's in software engineering from Carnegie Mellon. Since then I've interviewed at OpenAI and Meta for AI-native roles, and watched this exact architecture become the standard for what they test.
This plaque is on my desk.

"For Austin Starks, honored for passing 10 billion tokens."
Module 1 · Who This Course Is For · 2 min 47 sec
What It Means
The leak didn't reveal magic. It revealed a loop.
Everyone who's read the breakdown knows the same thing: at the center of Claude Code is a loop. The model thinks. It picks a tool. The tool runs. The result comes back. Repeat until done.
That loop has a name. It's called ReAct, from a 2022 paper out of Google Research. Cursor runs on it. Claude Code runs on it. Every production AI agent you've used runs some version of it.
Here's the actual structure from src/query.ts, the 1,729-line file at the heart of the leak. Most people miss the key detail: tools start executing while the model is still streaming.
The loop that makes Cursor feel fast is the same pattern. Read tools (grep, file read, search) run in parallel. Write tools get an exclusive lock. The model doesn't wait for a tool to finish. It's already streaming the next thought while the tool runs.
The loop is the core. But the loop alone doesn't get you to production. The rest of this series covers what wraps around it: how controllers route decisions, how the orchestration loop manages autonomy without going off the rails, how memory lets an agent improve across sessions instead of starting cold every run, and how you measure whether any of it is actually working.
Most people using Cursor or Claude Code are operating on intuition. They can't explain why it works when it works or why it fails the way it does. They can't evaluate whether the next tool is actually better or just better marketed. That's fine until you're the one expected to build something, own something, or interview for something. Then it matters.
From the course
"I recommend you take a look at the ReAct paper. You don't have to read the entire thing. Drop it in ChatGPT or Claude. Read the abstract. Understand it. Because this is the basis of all AI agents today."
Who This Is For
Three types of people need this course.
You're a SWE or PM at a company that just shipped an "AI roadmap." Your team is using the word "agent." You're expected to own something in this space within the next two quarters and you'd like to understand what you're actually building before that conversation happens.
You have an AI-native systems design interview coming up. Meta, Google, Anthropic, xAI still test databases. Now they layer agent architecture on top: design a system that can reason, remember, and self-correct. This series covers exactly what they test. I know because I went through it.
You use Cursor or Claude Code every day and you've started wondering what's actually happening. Why does it fail the way it does? Why does Cursor feel smarter than Claude Code when both use Claude under the hood? What would you change if you could get inside it? That's what this series answers.
How technical is it?
Semi-technical. There are code snippets and diagrams. You are not expected to reproduce them. The goal is understanding how agents work, not memorizing syntax.
The Full Picture
Big tech is now interviewing for four specific things. This series covers all of them.
The AI-Native SWE interview is a different animal. Linked lists are not the bottleneck anymore. The systems design component now includes agents that reason, remember, act, and self-correct. Here's exactly what they're testing, and what every article in this series teaches.
Controllers & Prompt Engineering
What actually separates a language model from an agent. System prompts, tool schemas, JSON generation, function calling, and the controller layer that routes every decision. MCP servers are just tools with a standardized interface. You need to know why that matters.
"Walk me through how you'd architect the prompt layer for a multi-tool agent."
Watch video
The ReAct Loop & Orchestration
The Reasoning + Acting loop is the engine behind every serious agent: Claude Code, Cursor, Devin. How it works, how it fails, and how to make it production-safe with approval modes, permission layers, and circuit breakers that stop runaway agents.
"Describe the ReAct pattern. How would you prevent an agent from taking a destructive action?"
Watch video
Memory Architecture
In-context, external, episodic, semantic: four tiers of agent memory and when to use each. Why most agents feel dumb after the first few messages, how retrieval-augmented generation fixes it, and the architecture that lets an agent improve across runs instead of starting cold every time.
"Your agent's context window fills up mid-task. How do you handle it without losing state?"
Watch video
Evaluation & Observability
How do you know if your agent is actually getting better? Traces, LLM judges, weighted rubrics, and the feedback loop that closes the improvement cycle. The optimization trap is real: an agent can score perfectly on your metric and still be completely wrong in production.
"How would you build an automated evaluation pipeline for an agent? What would you measure?"
Watch video
Pop Quiz
Quick check before you go to Module 2.
Question
What is the main difference between ChatGPT and a bare language model like the OpenAI Playground?
Question
When an AI agent generates a JSON tool call, does the JSON itself perform the action?
The Series
Four more articles. Each one will change how you think about AI.
This article is just the setup. The next four cover real architectures, real failures, and the exact decisions that separate agents that work from agents that break.
 MODULE 02 of 05
MODULE 02 of 05
Controllers & routing
Everyone thinks ChatGPT is an AI agent. It's not.
 MODULE 03 of 05
MODULE 03 of 05
Orchestration & autonomy
Coinbase calls their chatbot an agent. I got fired for building a real one.
 MODULE 04 of 05
MODULE 04 of 05
Memory & context
Cursor beats Claude Code. Here's the memory architecture that proves it.
 MODULE 05 of 05
MODULE 05 of 05
Evaluation & feedback loops
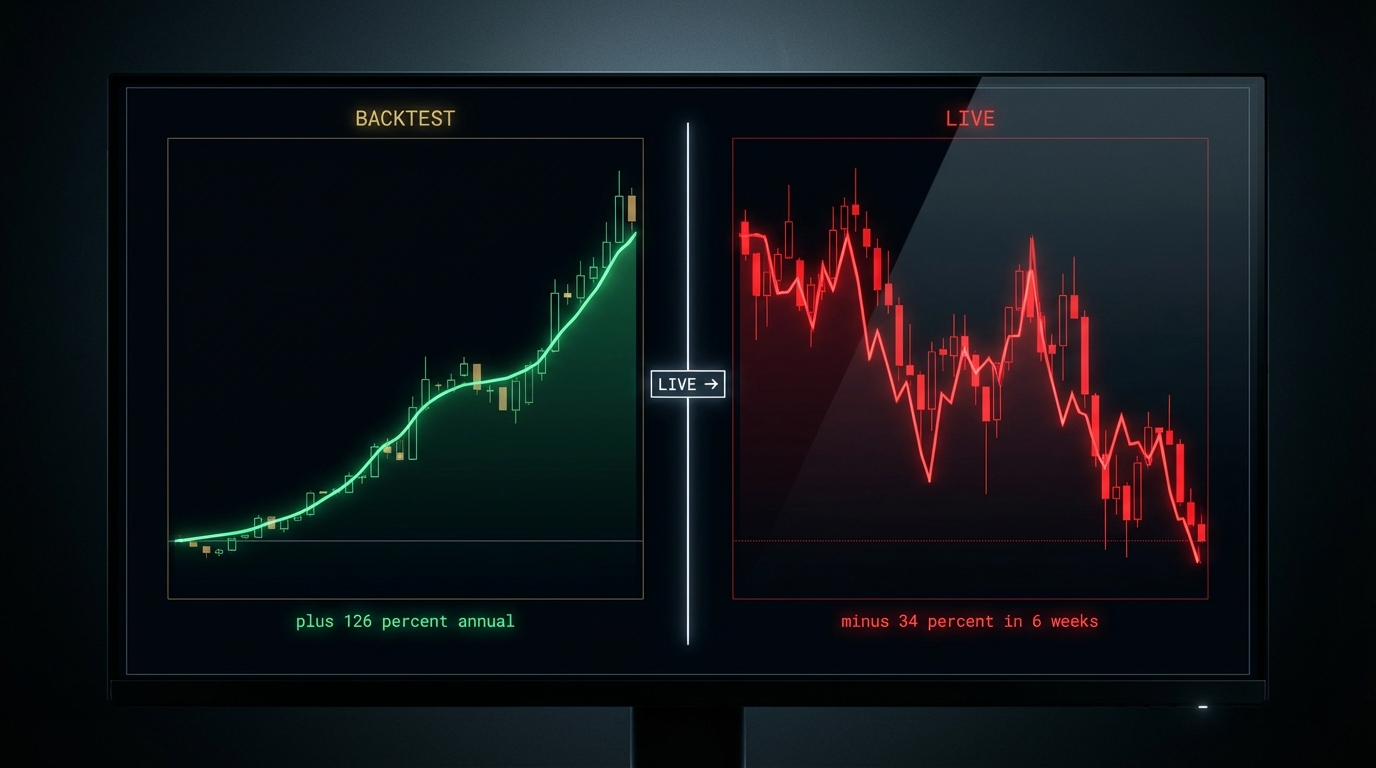
Your AI trading bot will fail because it's optimizing the wrong thing.
No comments yet.