
If you are a serious AI practitioner, you know that Cursor is better than Claude Code.
The community lands in the middle. I land on the right.
The surveys disagree for now, but they won't for long. The Pragmatic Engineer's March 2026 survey of 906 engineers found Claude Code has 46% developer love vs Cursor's 19%. Among the 55% of developers who regularly use AI agents, Claude Code is the clear leader at 71% usage.
And look, Claude Code has real advantages. The Max plan ($100-$200/month) gives you parallel agents running all day with high usage limits. It's token-efficient, using 50-75% fewer tokens than older Anthropic models with equal or better output. Its SWE-bench scores are genuinely better. Claude Opus 4.6 is an exceptional model.
But I use Cursor. The UX is in a different league. Composer 2, released March 2026, is an insanely good model that actually works fast (unlike Opus which can take 30+ minutes per iteration). It can maintain coherence across hundreds of actions, plan across files before writing a single line, and iterate without losing track.
It lets me switch models per task. The interface is polished, keyboard-driven, and built for developers who ship things, not for people who like living in a terminal. And most importantly, it does a better job managing memory. Cursor's memory is your codebase, and your codebase doesn't lie.
That last point is the one most people argue about without understanding the engineering underneath. This article is about the engineering underneath. Module 4 of the AI Agents from Scratch course is about memory. Here's the full picture.
The problem every agent builder hits
Module 4, Lesson 1: Memory. From stateless models to vector databases and structured retrieval.
The base model has no memory. You knew that. But the implications for agents are worse than they sound.
Every time you start a new session, the agent starts from zero. It doesn't know what it built last week. It doesn't know which strategies it already tested. It doesn't know that you told it three sessions ago to always use 3-year backtests instead of 1-year. It has to rediscover everything.
In practice, that means the agent wastes your iterations on exploration that already happened. When Aurora launched without memory, it took 20+ iterations just to get to a half-decent strategy on every single run. The agent was smart. It just couldn't remember. Every run was a cold start.
Memory is the engineering layer that fixes this. The question is how.
Check Your Understanding
Why does an AI agent forget everything between sessions, even if it performed well the last time?
Four ways to give an agent memory. Only one scales.
There's a spectrum of approaches, from naive to production-grade. Most tutorials only cover the first two. Here's all four, including what Cursor and Claude Code actually do.
How Claude Code actually handles memory: no vector database
When Anthropic accidentally shipped Claude Code's source code in March 2026 (a Bun bundler bug exposed 512,000 lines of TypeScript via an npm source map), the most surprising finding wasn't the hidden virtual pet system or the "undercover mode." It was the memory architecture.
The memory architecture is plain markdown files in a directory with a 25KB index cap. It doesn't use RAG or Pinecone. Anthropic invested in the maintenance loop instead of the storage layer.
The memory system stores notes as plain markdown files in a memdir folder with an ENTRYPOINT.md index. Memory types: user preferences, feedback and corrections, project context, reference pointers. One-line entries, 150-character limit each, index stays under 25KB.
The interesting part is Dream Mode: a 4-phase consolidation loop that runs during idle time.
The prompt literally says: "Don't exhaustively read transcripts. Look only for things you already suspect matter."
LLMs are already good at reading and writing text. The hard part of memory isn't storage. It's maintenance: keeping notes accurate, consolidated, and bounded. That's what Dream Mode solves, and it works.
There's a deeper limitation too. Dream Mode memory is an LLM writing notes about what it thinks happened. Those notes can drift. They can miss things. And as you'll see, they can be poisoned when the underlying data is wrong. Claude Code's memory is only as reliable as the model that wrote it.
Cursor's memory is your codebase. It doesn't interpret. It doesn't summarize. It indexes what's actually there. For software development, that's the more trustworthy foundation.
How Cursor handles memory: a vector index of your codebase
Module 4, Lesson 2: How vector databases and retrieval-augmented generation give agents semantic memory at scale.
Cursor solves a different problem than Claude Code. It's not trying to remember what you told it last week. It's trying to navigate a codebase it has never seen, at a scale where reading every file would be prohibitively expensive.
The architecture: Cursor uses tree-sitter to parse code into Abstract Syntax Trees, creating semantic chunks (classes, methods, functions). Those chunks get converted to vector embeddings and stored in Turbopuffer, a specialized vector database.
Change detection uses Merkle trees (the same structure behind Git and Bitcoin) to identify exactly which files changed without re-indexing the whole codebase.
If you haven't worked with vector embeddings before: an embedding model converts any piece of content into a list of numbers that captures its meaning. Things that mean similar things end up close together in that space. At query time, your question gets embedded the same way, and the database returns whichever stored chunks are mathematically nearest to it.
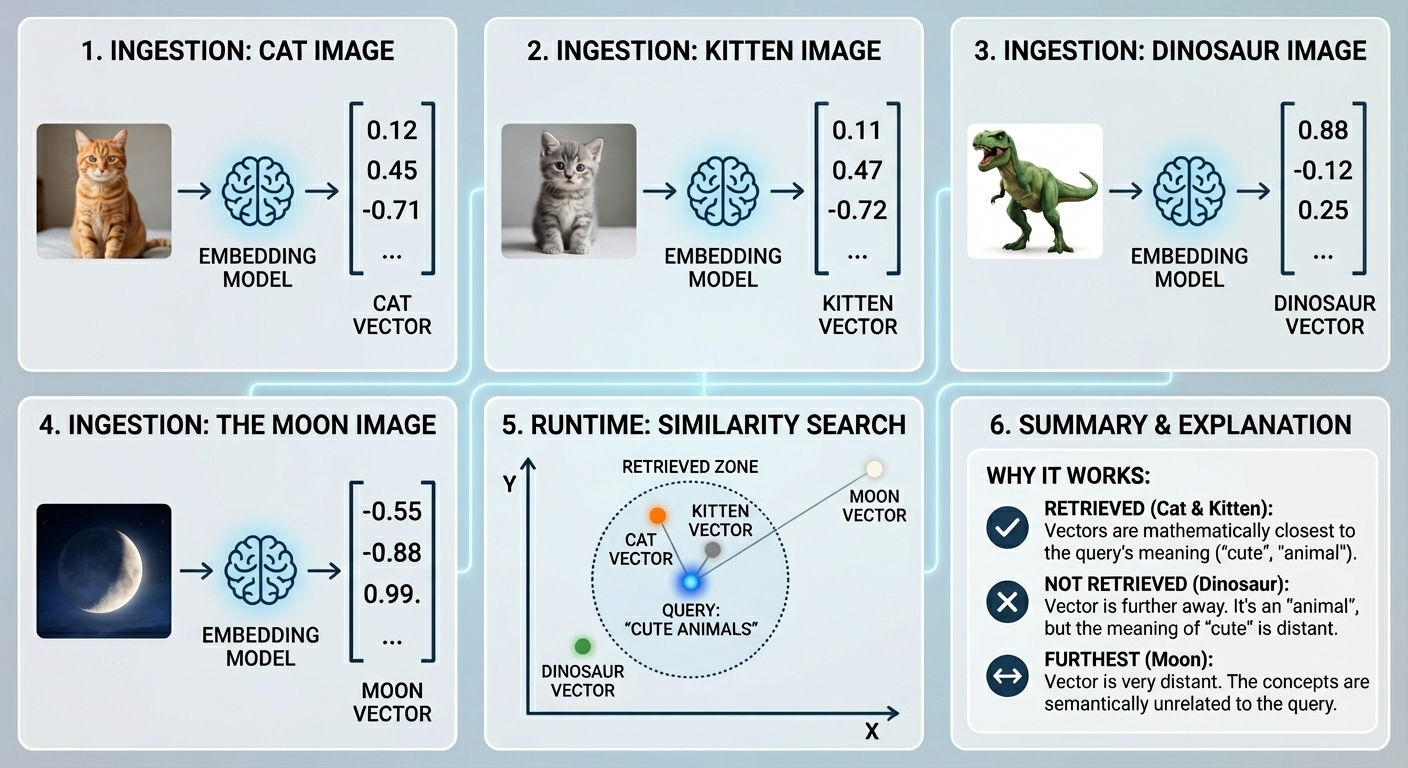
Ingestion converts each item to a vector. At query time, similarity search finds the vectors closest in meaning to your query — not just keyword matches.
Cursor runs this same pipeline across your entire codebase. Every function, every class, every method gets chunked, embedded, and stored. The pipeline has five steps:
This is why Cursor wins for active development. If you ask it about a function defined three directories away, it finds it. If you're refactoring a class that 40 files reference, it knows about those files without you telling it. The memory is your codebase, indexed semantically, updated incrementally.
The "rules" system (`.cursor/rules/`) is the persistent context layer on top of this: project conventions, coding standards, architectural decisions. Unlike Dream Mode, Cursor doesn't write these for you. You write them. The model reads them at session start.
Cursor's persistent rules panel out of the box. Empty. You write the memory. The codebase index handles the rest.
Cursor's memory wins where it counts for development: it knows your codebase as it actually exists, not as an LLM summarized it. The source of truth is the code itself, updated incrementally, always accurate. That's what makes it reliable at scale.
| Capability | Claude Code | Cursor |
|---|---|---|
| Storage format | Markdown files (25KB index cap) | Vector embeddings (Turbopuffer) |
| Auto-writes memory | Yes (Dream Mode, idle consolidation) | No (you write the rules) |
| Codebase navigation | Limited (text search, no semantic index) | Excellent (AST parsing + semantic retrieval) |
| Cross-session learning | Yes (Dream Mode carries forward) | Partial (rules persist, embeddings persist) |
| Domain-specific queries | No (flat text, no structured fields) | No (semantic similarity, not typed metadata) |
| Memory poisoning risk | Yes (bad sessions corrupt future context) | Low (codebase is source of truth) |
Check Your Understanding
What is retrieval augmented generation (RAG) and when do you actually need it?
What NexusTrade does differently: structured memory with semantic queries
Vector databases are great for fuzzy text matching: find me code that does authentication. They are terrible at structured constraints: find me only backtests for NVDA where the Sharpe ratio was above 1.5. For trading, memory isn't fuzzy. It's math.
Neither markdown files nor vector embeddings solve the specific problem of an agent that runs trading research. After an agent session, what you need to remember isn't just "what happened."
It's structured: which tickers were tested, which strategy types worked, what the backtest metrics were, what procedural lessons apply to future runs of similar tasks.
NexusTrade stores memory as typed AgentSummary records in MongoDB. After each run (or at iteration 20, when the context window summarizes), the agent writes a structured document:
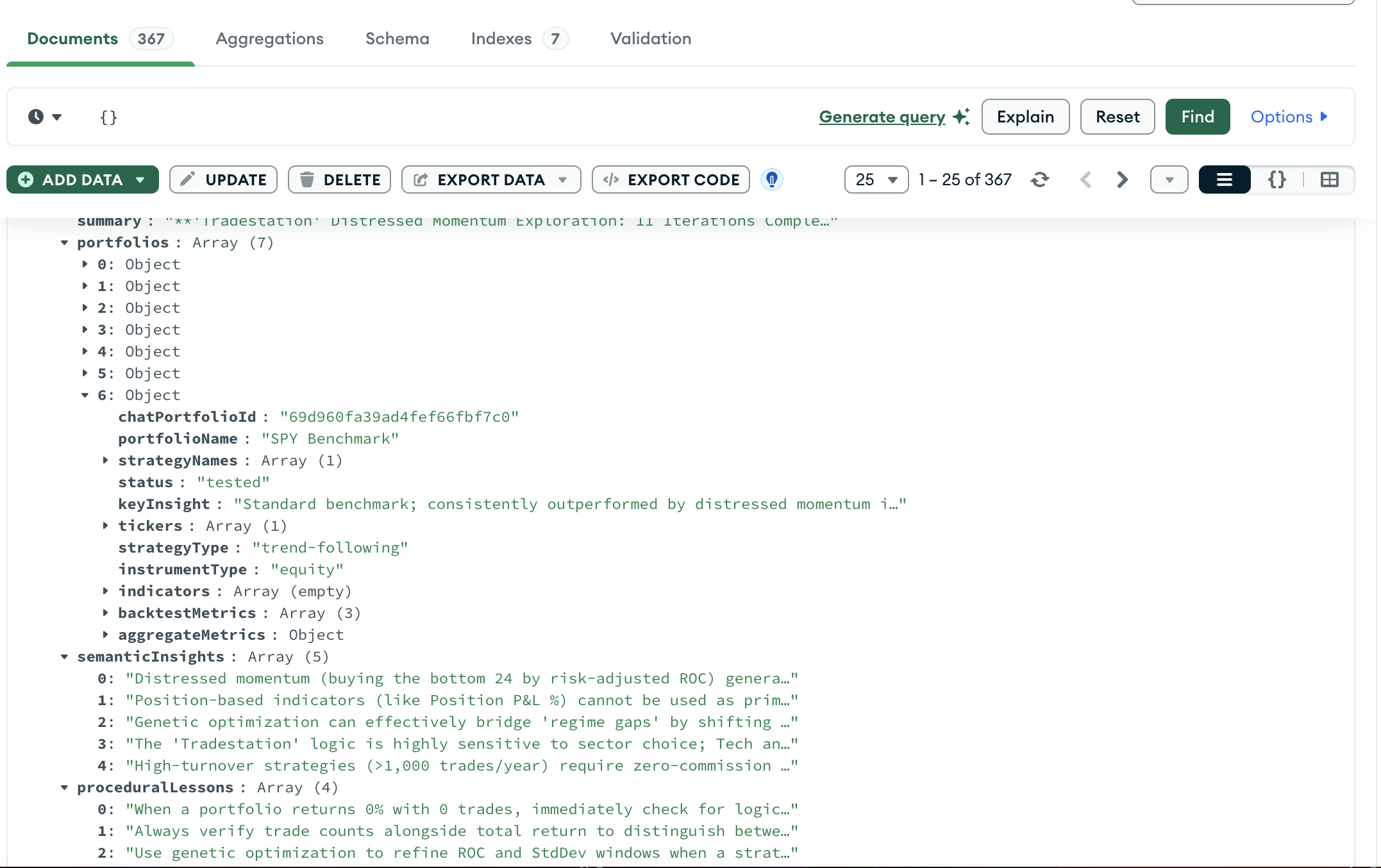
An actual AgentSummary document in production. Structured fields: portfolios with tickers, strategy type, backtest metrics. Flat arrays: semantic insights, procedural lessons. Indexed for targeted retrieval.
Each document has: semanticInsights (up to 24 deduplicated patterns from this run), proceduralLessons (up to 12 meta-lessons about how to run better next time), and structured portfolio records with tickers, strategy type, instrument type, options structure, and backtest metrics per period.
Before a new agent run, a separate fast LLM call reads the current conversation and extracts structured MongoDB query fields: which tickers are relevant, which strategy types, equity or options, any keywords.
Then getInsightsMatchingQueries runs a targeted query against the index and injects the matching past summaries into the planner.
The agent doesn't get everything. It gets what's relevant to this task. If you're asking about NVDA options, it pulls past NVDA options runs. If you're asking about momentum strategies, it pulls past momentum runs. The retrieval is typed, not fuzzy.
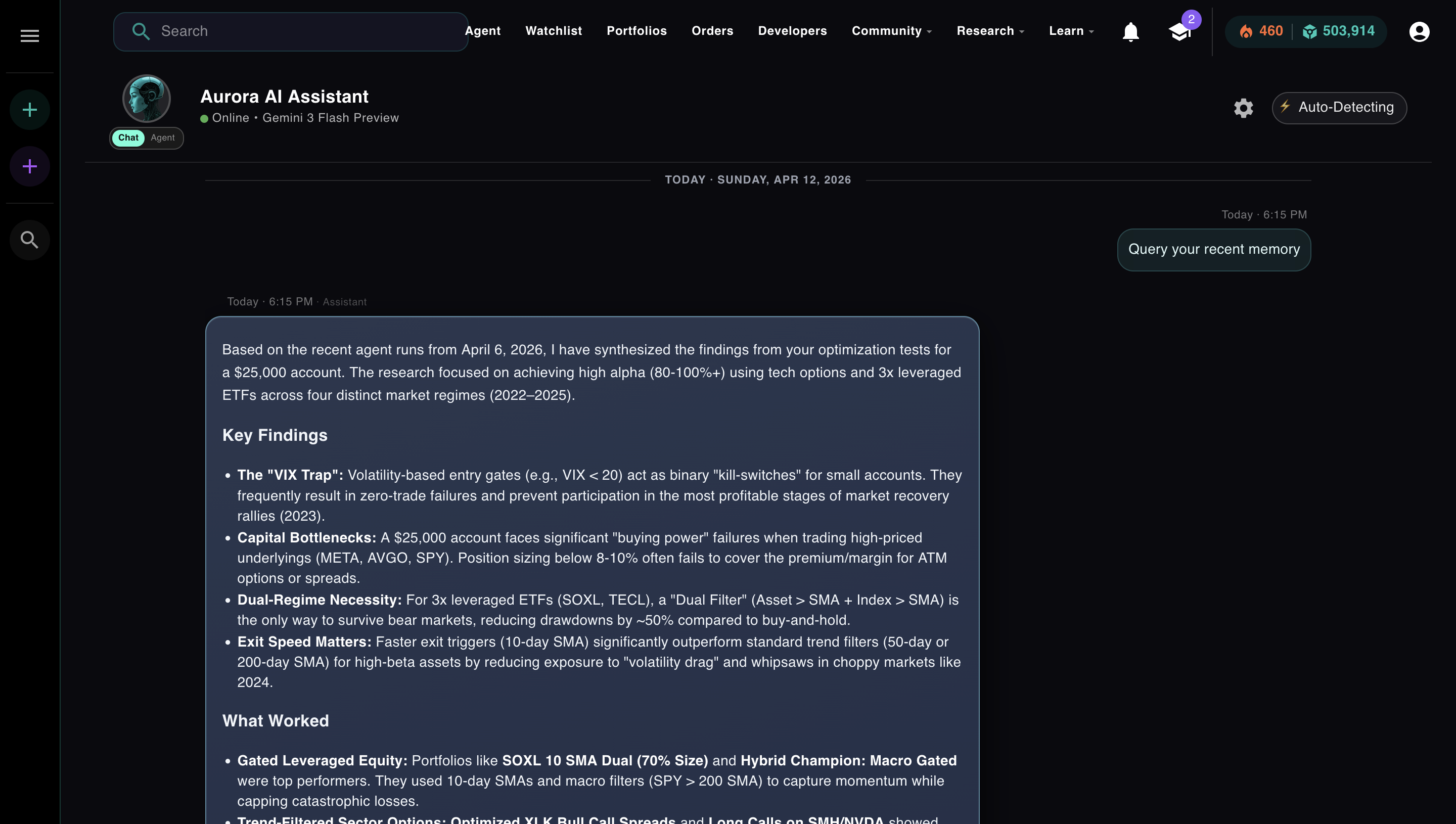
Aurora synthesizing findings from past runs before starting a new one. "The VIX Trap," "Capital Bottlenecks," "Exit Speed Matters" — real patterns from real sessions, queried and injected at runtime.
The result: agents that start sessions already knowing what worked, what failed, and what to avoid. Cold starts went from 20+ iterations to a fraction of that. The agent doesn't explore what it already knows.
The part nobody talks about: memory poisoning
Founder's Note
During the options trading beta, I had a bug in the spread backtest engine. Credit spreads were being calculated incorrectly — the math was off in a way that sometimes showed catastrophic losses on strategies that would have been fine, and sometimes showed massive phantom gains on strategies that would have lost money.
The agent ran. It learned from the results. It wrote those lessons into memory. "Bull call spreads on META led to catastrophic losses." "Mean-reversion spreads on NVDA are unreliable." None of it was true. The strategies weren't bad. The backtester was wrong.
The next runs came in already poisoned. The agent avoided spreads entirely. It was confident about it — it had "evidence." Users noticed their agents weren't exploring options strategies the way they used to. I couldn't figure out why until I traced it back to the memory layer.
The problem wasn't the agent. The problem was the memory, and you can't just delete it. It was mixed in with valid insights from runs that were fine. Surgical deletion wasn't practical.
The fix was insightsPipelineVersion. Every AgentSummary document is written with the current pipeline version number. Retrieval only returns documents that match the current version exactly. If I bump the version, every old document goes silent instantly. They stay in the database for analytics, but they stop matching the filter and stop being injected.
We're now on version 6. Each version bump corresponds to a bug fix in the backtesting engine that would have corrupted agent memory if the old summaries kept being used. The versioning system is a survival mechanism for production memory systems where the data generating the memories can be wrong.
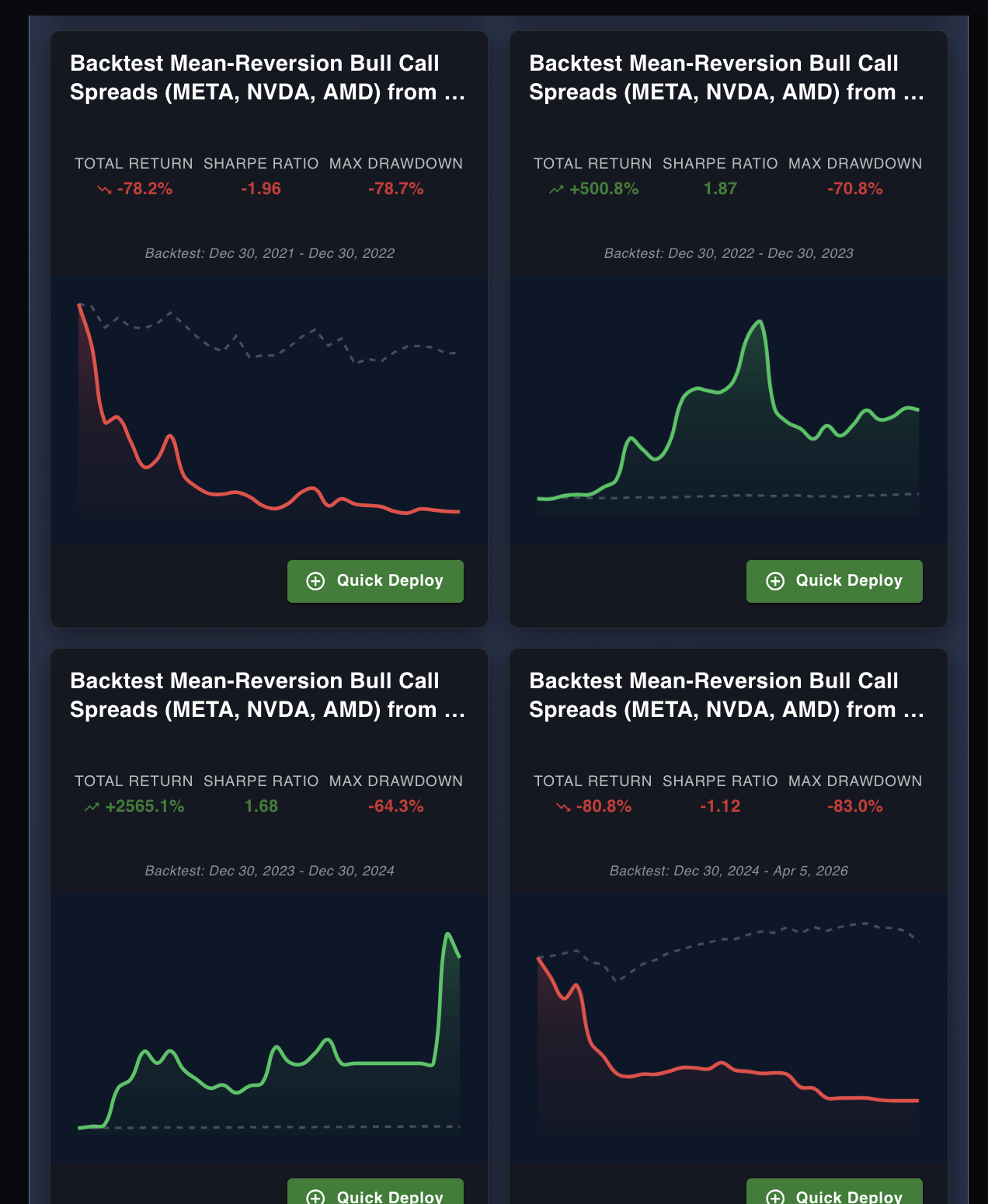
The results that poisoned agent memory. The red ones show real-looking losses. The green ones show gains that never existed. The agent learned from all four — confidently. None of it was true.
This is the risk neither Cursor nor Claude Code faces at the same level — their memory is about general development context, not quantitative results that depend on correct underlying calculations. When your memory is downstream of a system that can be wrong, you need a versioning mechanism. A flat markdown file doesn't give you one.
Memory that makes the agent better over time
Storing memory is one thing. Using it to improve is another. NexusTrade runs a background worker that scores every completed agent run, extracts what worked, and injects those patterns into the next run automatically. The cycle looks like this:
A prompt enhancer queries top performers and extracts their successful tool sequences. A planner enhancer finds few-shot examples relevant to the current task by keyword. Both cache results for 5-10 minutes and inject learned patterns into future prompts automatically.
Most agents plateau at run 1. The same output on run 50 as run 1, because nothing carries forward. This is the gap between a demo and a system. The flywheel is what crosses it.
Module 4
Reading about memory isn't the same as using it.
The concepts in this article are straightforward on paper. File dumps, LLM summarization, vector embeddings, structured queries. But the questions that actually matter only come up when you run it: what does Aurora remember from your past sessions? What gets injected, and what gets filtered out?
Module 4 of AI Agents from Scratch puts you in the system directly. You query Aurora's memory and see what it has stored from your past runs. You watch the LLM read your prompt, generate query fields, pull matching summaries, and inject them before the agent starts.
You'll see exactly what the agent knows before it knows what you're about to ask.
This is not a simulation. It's the live production system, and what it has stored is specific to you.
Free. No credit card. Query Aurora's memory, see what it remembers from your trading style, and watch how versioned insights protect it from getting poisoned by bad data. Takes about 15 minutes.
Start Module 4 Free → Or open Aurora directly →
No comments yet.