
$25,000 Public Portfolio Challenge · Episode 5
An AI built this trade. An AI is watching it. Tuesday at 9:30 ET, $25,000 finds out if any of it works.
Five frontier models. Sixty iterations of one parent agent. Thirty portfolio variants. Two spreads in the approval queue right now, waiting for me to press execute. A watchdog that's already fired three times against an empty portfolio, just to confirm the cron, the trigger, and the chat-report path all work end to end.
 Austin Starks
✦ Founder, NexusTrade
✦ May 2026
✦ 12 min read
Austin Starks
✦ Founder, NexusTrade
✦ May 2026
✦ 12 min read
The Setup
Tuesday at 9:30 ET, $25,000 of my own money goes into a trade I did not design.
Five AI models built it. Thirty portfolio variants got tested. A watchdog has fired three times against an empty portfolio, just to confirm the wiring works end to end before there's anything at stake. As of Monday evening, two spreads sit in the approval queue.
I press execute tomorrow at open.
The Public Portfolio Challenge has held at exactly $25,000.00 for two months. The number on the screen has not moved because I have been waiting until I trusted the deploy.
I am ready now. The first positions open Tuesday morning.
Four weeks ago I had a software engineering job at Coinbase. Their legal team was threatened by what I built, and fired me without warning. The week after I lost it I started shipping thirty commits a day. This article is what four weeks of nothing-else-to-do produced.
Three things mattered.
The data platform got rebuilt. I moved 3.85 TB of price and options data off Google Cloud onto Tigris in a single week. The old system kept a local binary cache on every backtest machine, and a scheduled hydration worker had to wake those machines and re-import data before any backtest could run. The new one reads parquet on demand and joins NBBO quotes lazily. Data lands in Tigris and the next backtest reads it.
Options trading shipped. Premium-gated. Subscription limits across every tier. A held-position mark-to-market hot tier so paper traders and live traders see the same numbers. The whole stack from Rust pricing to React UI.
The agent's brain got bigger. A debate orchestrator that lets multiple AI subagents argue through a multi-phase pipeline with crash-resilient state. Recent-agent-memory commands so the agent learns across sessions. Subagent fuzzy model validation. The agent system can now spawn five other agents in parallel, wait without blocking a worker slot, and synthesize what they came back with.
That last one added another tool to the agent's toolkit, the kind of tool useful on a run like yesterday's bake-off. The 24 hours since closed the rest: atomic multi-leg spread submission, side-aware fill prices wired through to the UI, stale-quote rejection at the trader, and structured error handling on the schema path the agent had to route around yesterday. If you want the architecture under the hood, I taught it as a five-module course in April. The rest of this article is what happens when you actually run it on real money.
Saturday afternoon · May 2
I gave my agent one prompt. Five hours, 1,355 API calls, $42 in compute, one strategy.
The prompt was simple. I named the five frontier models I wanted to compare and asked which one could build the most profitable options strategy on my watchlist or my investment philosophy of fundamentally strong innovation stocks. Then I asked for a comprehensive markdown report with a table and the top three winners. That was it.
The agent's planner classified the request as a model bake-off rather than a debate or a single-agent run, then spawned five subagents in parallel. Each subagent ran the same options-strategy task on a different frontier model. Same task, distinct models, parallel execution.
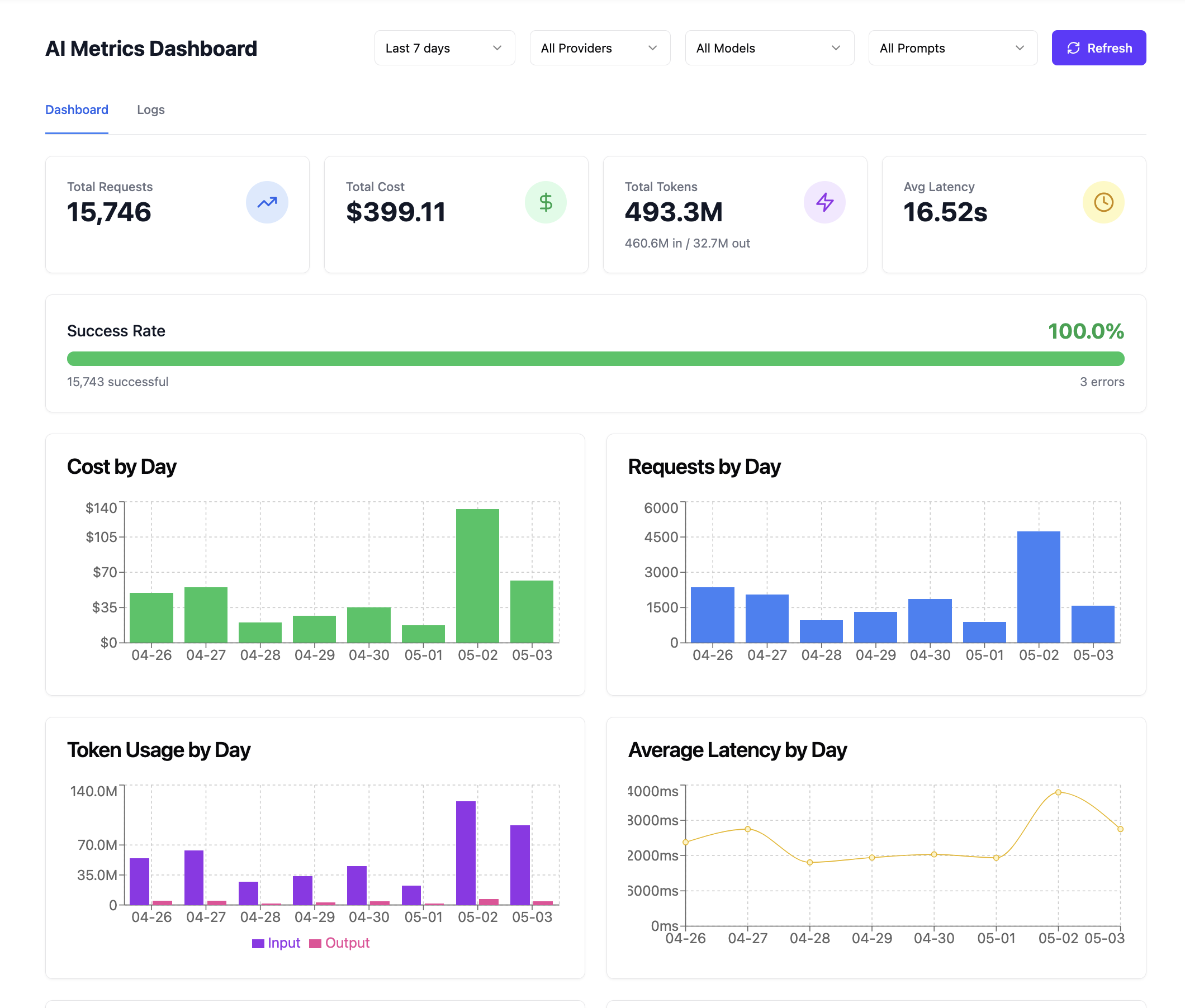
Gemini 3 Flash drove most of the cost ($30.73 across 1,066 calls) because it was both running its own subagent and powering the parent agent's executor loop. The other four models split the rest. Kimi K2.6 ran the longest of the dedicated subagents at 15 iterations and $5.38 in compute, and ended up producing the strategy structure I deployed. GPT-5.4-mini was the failure: it spent $0.28 retrying the same tool error and gave up at iteration 5.
What that actually looked like, step by step.
The agent ran on a ReAct loop: thought, action, observation, thought, action, observation, until the task was done. That's the architecture every modern agent uses, including Cursor, Claude Code, and the one that just shipped my trade. Click through the steps below to see the real trace from yesterday's run.
User · sends task
One prompt, sent at 6:26 PM ET on May 2. The agent moves to a planning phase before calling any tool.
💬 Planner · iteration 0
A separate planner prompt runs first. Its job is to classify the request and pick a strategy shape: single agent, debate, or parallel bake-off.
⚡ Action · createSubagents (iteration 2)
Five children spawn, each on a different frontier model. The parent then yields its worker slot via yieldForSubagents: true. It writes a pendingComputation breadcrumb to MongoDB and stops holding the slot. A wake-loop fires the parent again the moment all five children hit terminal.
👁 Observation · subagents complete (iteration 3)
Two models from different vendors landed on the same delta structure. Different reasoning paths, same destination. Caveat below: they were not blank-slate independent. Every subagent inherited the same prior knowledge from the agent's memory layer.
⚡ Action · Edit Portfolio
The next backtest came back with the exact text: "Schema incompatibility: BSON error. Kind: A deserialization-related error occurred. Message: missing field type." A bug in my own Edit Portfolio code. I shipped the fix the same evening, but by then the agent had already routed around it.
🔧 Recovery · Create YAML Portfolios
OpenOption, CloseOption, LaunchAgent) was missing the type field. Instead of patching the broken path, the agent called a different tool: Create YAML Portfolios. Built a fresh portfolio named "Optimized Innovation Challenge" with valid schema, backtested it successfully, then re-applied those validated strategies back onto the live Public Portfolio Challenge.My own platform tripped my own agent. The agent diagnosed it and routed around me without asking for help.
✅ Final · Public Portfolio armed
The agent ran for 60 iterations and hit max-iterations before issuing a final structured answer. The work landed anyway: by the time it stopped, the live portfolio held the validated strategies, the watchdog was scheduled, and the platform was armed.
Module 3 Lesson 1 · Orchestration · the ReAct loop, in 12 minutes
Three of the four completing subagents landed on bull call spreads. Kimi K2.6 and DeepSeek V4-Pro, from different vendors, picked the exact same delta structure. They didn't arrive at this independently. The agent system has a memory layer (structured AgentSummary records queried and injected into every run), and one of the priors fed to all five subagents was an observation from a past run that 0.50/0.20 BCS worked on this universe. What you're seeing is not five blank-slate experts converging. It's three architectures validating a remembered hypothesis from different angles. Convergence under shared priors is faster validation, not stronger validation. That distinction is the whole point of the architecture, and the failure modes that come with it (including memory poisoning when the underlying data is wrong) are covered in Cursor beats Claude Code. Here's the memory architecture that proves it.
The Five Subagents
What each model actually built.
Subagents run as independent agents inside the same conversation. Each one gets a task, runs its own ReAct loop for up to 25 iterations, and returns one structured result to the parent. The parent yields its worker slot the entire time. Module 3 Lesson 4 covers exactly how that orchestration works.
Here is what each of yesterday's five subagents produced:
Three of four completing subagents landed on bull call spreads. Kimi and DeepSeek picked identical deltas. They weren't blank-slate independent. Every subagent inherited the platform's structured memory of past runs. This is compounded validation, not independent convergence.
The Audit
The number was not the question. Survival was.
The agent kept running after the bake-off. It tested thirty more portfolio variants over the next several hours. Different filter combinations. Different position sizing. Different stop ladders. Different universe slices. Then it backtested every one, ranked them, and posted the comparison to my chat.
Three of the results were eye-popping.
| Variant | Window | Return | Sortino | Max DD | Verdict |
|---|---|---|---|---|---|
| Stock-SMA50 + 25% per-name allocation | 2023-2026 | +6,130% | 2.66 | -65.4% | Rejected: drawdown |
| SPY-SMA200 + RSI50 + 25% per-name stop (deployed, by regime) | 2022 bear | -15.2% | n/a | -15.2% | Defense worked vs SPY -18.4% |
| 2023 recovery | +34.8% | n/a | -22.4% | Beat SPY +26.2% | |
| 2024 chop | +30.3% | n/a | -35.8% | Beat SPY but eats premium | |
| 2025 to now | +59.1% | n/a | -32.7% | Beat SPY +23.6% |
The Stock-SMA50 row is verified from a single 2023-2026 backtest the agent ran. +6,130% return looks tempting until you see the 65% drawdown. A 65% drawdown vaporizes two-thirds of the account. No retail trader holds through that without flinching, regardless of what the backtest's eventual recovery line says. Off the table.
The deployed variant rows are verified from a separate four-regime stress test the agent ran on the live portfolio: 2022 bear, 2023 recovery, 2024 momentum-chop, 2025 to now. Each row is a real backtest with real fills and real drawdowns. The 2024 row matters most. The strategy gave back 35.8% peak-to-trough in a year SPY only dipped 9%. That isn't robustness. That's a known fragility regime: bull call spreads pay premium when underlyings chop sideways before resolving, and 2024 is what that costs. The structure pays +30 to +60 percent in the regimes that resolve. It bleeds in chop. The drawdown floor on this portfolio is set by chop, not by bear markets.
The platform's first move on $25,000 was a defensive variant, not the highest-return one. If that account blows up, the platform does not get a second chance to prove itself.
Saturday night · 9:27 PM ET
Before any money was at risk, the watchdog fired itself.
The portfolio does not just hold strategies. It holds a tenth strategy whose only job is to launch another agent. That second agent reviews the portfolio, reads market data, and proposes defensive trades back into my chat for approval. Every Monday morning, automatically. Or any time SPY breaks below its 200-day SMA, the moment it crosses.
The watchdog has fired three times since deployment: Saturday at 8:39 PM ET (hit max iterations on a deeper review), again at 9:27 PM ET (clean run, completed in three iterations), and again Monday evening as scheduled. The 9:27 PM Saturday run is the cleanest paper trail. It pulled live market data through the same Stock Screener tool the bake-off subagents used, and posted this report into my chat:
Watchdog Run · 2026-05-03 01:27 UTC · Status: completed
Asset trend analysis: SPY $720.65 above 200-day SMA $670.94, bullish. NVDA, AVGO, GOOG all bullish on their 50-day SMAs. META trading below its 50-day SMA at $608.75 vs $630.36, trend broken.
VIX 16.99, stable, supportive of the broader trend.
Portfolio: 0% drawdown, $25,000, no open positions.
Defensive recommendation: suspend new META entries until price reclaims the 50-day SMA at $630.36. NVDA, AVGO, GOOG remain in healthy uptrends.
Status: safe.
The recommendation was already enforced by the mechanical entry rule. META's RSI sits at 43, below the threshold of 50. Two independent agents reached the same conclusion through two independent paths. The strategy and the watchdog agree. That redundancy is the design.
So the loop closes. An agent designed the strategy. An agent armed it. An agent watches it. An agent has already fired three times against an empty portfolio, just to validate the wiring. The real test of the watchdog is what it does on a portfolio that's actually carrying P&L, and that test starts Tuesday. Every weekly run is a fresh trace, fully visible. Every recommendation comes back to me to approve or override. Every order I sign off on goes through my own brokerage account.
Sunday and Monday · the last 48 hours
The last weekend went into the submit button.
Saturday's run armed the strategy. The 48 hours since made sure the trade can actually fire.
The strategy can be perfect, the regime sweep can prove it survives bear markets, the watchdog can be on call 24/7, and none of it matters if Tuesday's order goes in fragmented, or with a stale price, or with one leg that fills while the other one doesn't. Multi-leg options orders are unforgiving. A bull call spread with one leg filled and the other one missing is no longer a bull call spread. It's a naked call.
So Sunday and Monday went into the part of the platform you only see when you press submit:
- Atomic spread approval. When you approve a bull call spread in the UI, both legs go in as a single order. The two legs are linked at the submission boundary so the broker either takes both or rejects the whole thing.
- Side-aware fill prices. The approval card now shows the actual ask you'd pay on the long leg and the bid you'd receive on the short leg, instead of a midpoint estimate. What you approve is what hits the market.
- Stale-chain rejection. The Rust trader now refuses to submit an options order if its underlying chain hasn't been refreshed inside the last few seconds. If the data is stale, the order fails loud with an
OPTION_CHAIN_STALEaudit event in my chat, instead of finding out at fill. - Schema-error alerting. Schema-mismatch failures in the backtest worker now page me directly instead of silently failing into the void. The agent still has to route around the bug at runtime, but I find out the moment the next one hits.
- Per-portfolio account routing. Each order resolves its own brokerage account by portfolio, so a live-account order can never accidentally route through a paper account, or vice versa.
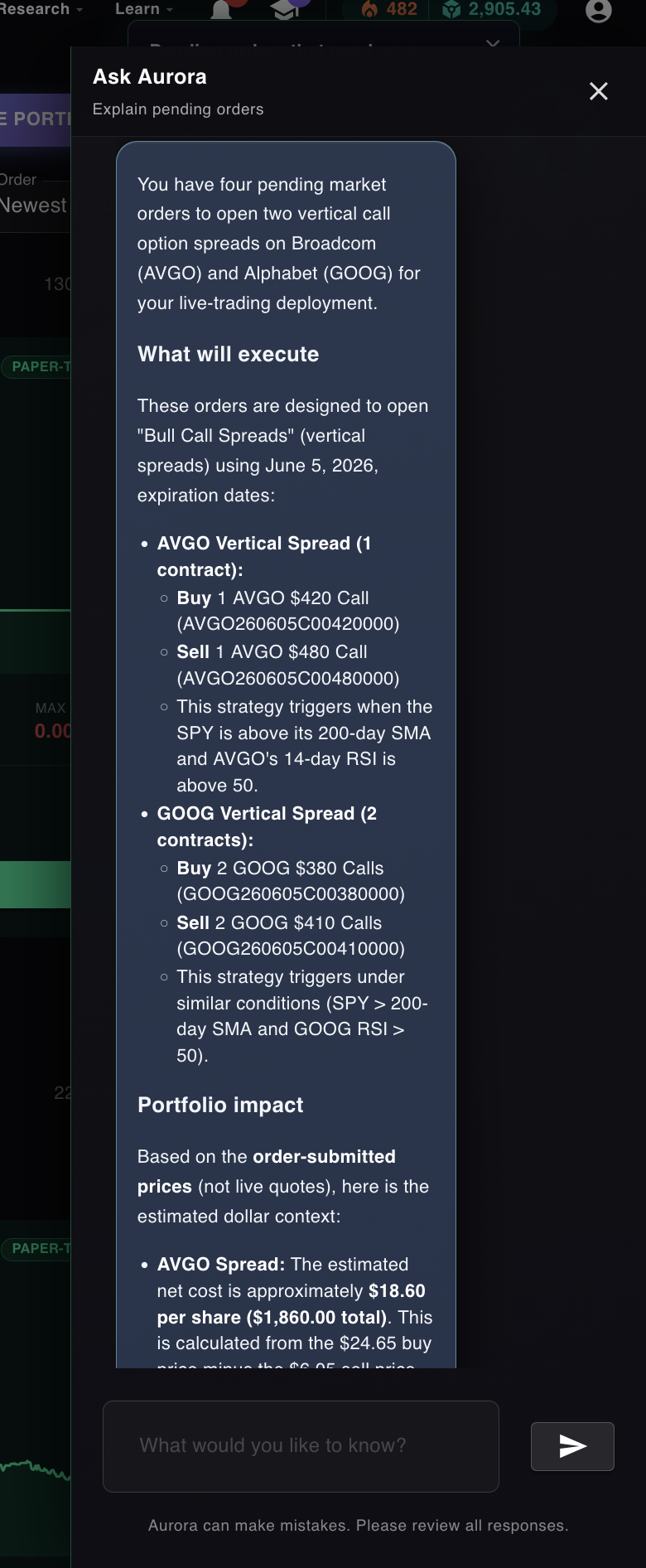
By Monday evening, two spreads were sitting in the approval queue. AVGO and GOOG. Aurora explained them in plain English when I asked:
Then, when I clicked through to actually approve them, the new atomic-spread modal opened:
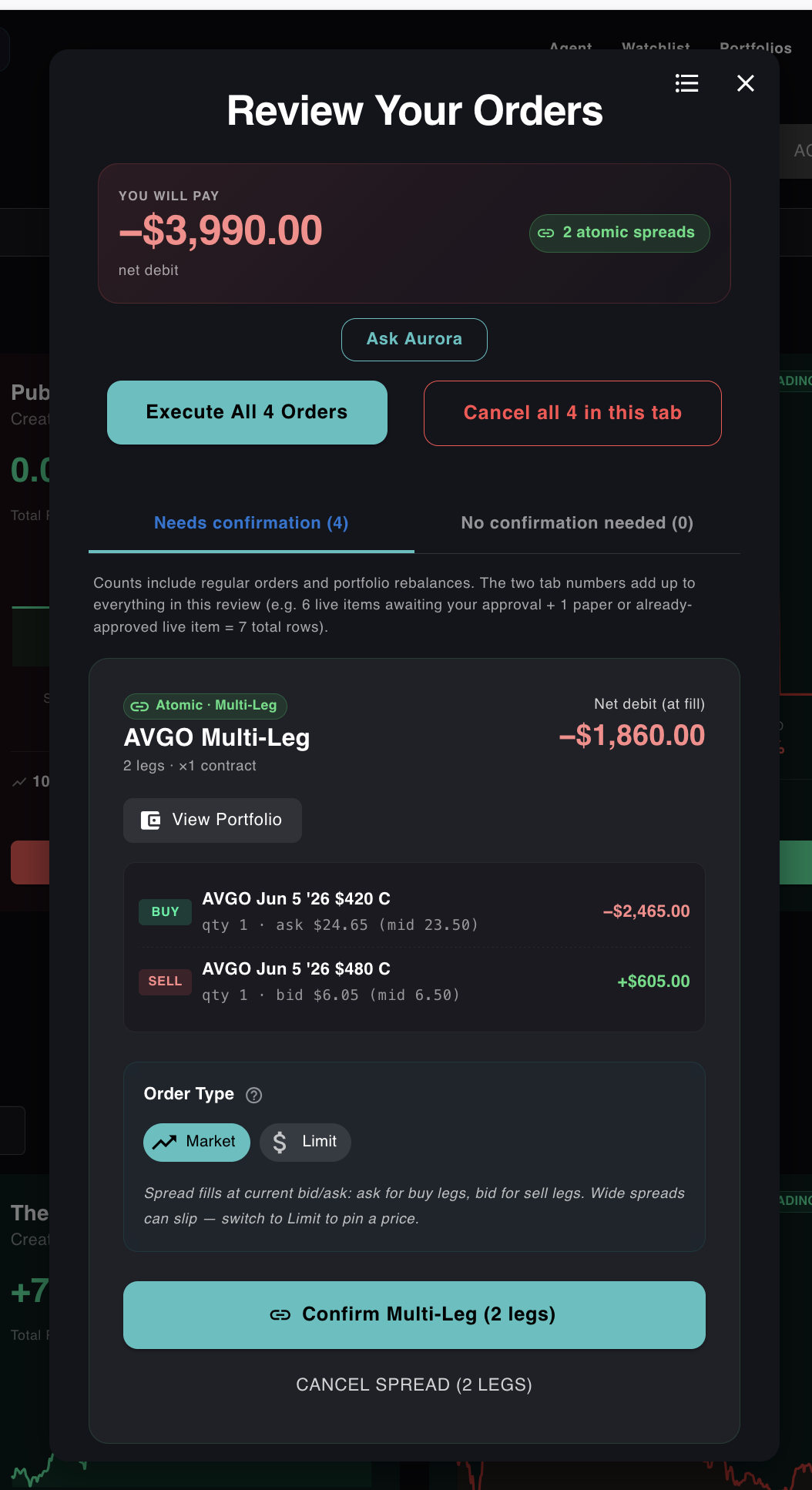
Net debit of $3,990 on the two spreads. Both broken out leg-by-leg with explicit ask prices on the long calls and bid prices on the short calls. The "2 atomic spreads" badge is the part that matters: each spread submits as a single linked unit. The broker takes both legs or neither.
The last commit landed about an hour before this article went up. Tuesday's trade goes through a path I now trust as much as I trust the strategy itself.
Tuesday · 9:30 ET
Two spreads in the queue: AVGO and GOOG.
The setup, exactly as it sits in the live portfolio:
- Bull call spread on each of NVDA, META, AVGO, GOOG
- Long call 0.50 delta, short call 0.20 delta, 30 to 45 days to expiration
- 10% of portfolio per name (up to 40% deployed when all four fire)
- Entry filter: SPY above its 200-day SMA AND the stock's 14-day RSI above 50
- Per-position stop: close any name when its position is down more than 25%
- Portfolio-wide exit: +50% target, -30% stop, 7-day-to-expiration time exit
Two stop layers. The macro filter handles regime risk. The per-name drawdown stop handles the ticker that breaks while the rest of the basket is fine.
Monday evening tick, 10:24 PM ET · pulled from the live OpenOptionSignal event
| Ticker | Price | RSI(14) | Status |
|---|---|---|---|
| SPY | $717.76 | n/a | macro filter ✓ (200d SMA $684.47) |
| AVGO | $414.86 | 53.90 | fires |
| GOOG | $379.45 | 73.86 | fires (extended) |
| NVDA | $197.68 | 35.64 | skipped (RSI < 50) |
| META | $609.70 | 18.23 | skipped (RSI < 50) |
Two spreads queue: AVGO and GOOG. About 20% of capital at risk, defined-risk by structure. NVDA and META are both correctly skipped because their 14-day RSI dropped below the entry threshold. NVDA's momentum cooled into a dip (35.64), META's collapsed (18.23). The mechanical filter is doing what it should: only opening a long-delta spread when the underlying has actual momentum.
GOOG fires despite a hot RSI of 73.86, which is extended territory. The bull call spread caps the loss at the debit paid no matter what GOOG does next, but the entry is hot and there is no point pretending otherwise.
A failure mode I caught while writing this
Saturday's watchdog reported NVDA as "bullish" because its price was above its 50-day SMA. The mechanical entry rule uses 14-day RSI > 50, a faster momentum filter that the watchdog doesn't check. So the two systems can disagree: a stock can sit above its 50-day SMA while its RSI is rolling over, which is what happened to NVDA between Saturday and Monday evening.*
*This specific failure mode has been fixed: the watchdog now evaluates the same conditions the live entry rule uses, so its weekly status report aligns with what the strategy will actually do at the next tick.
Regime stress test
The deployed strategy got tested through four separate market regimes before any money went near it. Each regime is its own backtest, not a slice of a single compound run:
| Regime | Period | Strategy | SPY | Drawdown | Verdict |
|---|---|---|---|---|---|
| Bear market | 2022 | -15.2% | -18.4% | -15.2% | Defense worked |
| Recovery bull | 2023 | +34.8% | +26.2% | -22.4% | Captured the rebound |
| Momentum trend | 2024 | +30.3% | +25.3% | -35.8% | Fragile |
| Current regime | 2025 to now | +59.1% | +23.6% | -32.7% | Strongest alpha |
The 2022 bear test is the data point I trust the most. That regime was outside the original optimization window. The strategy was simulated against it cold. The macro filter pulled the portfolio to cash for most of 2022 and lost less than SPY did. That is the test that proves the defense works when it has to.
The 2024 number is the one to call out. A 35.8% drawdown in a year SPY only dipped 9%. Bull call spreads on high-beta names give back premium when the underlying chops sideways before resolving its move. That trade-off is live in the portfolio because the structure exists to capture +30 to +60 percent in the regimes that resolve, and 2024 is what the same structure costs in the regimes that grind.
The Sharpe ratio lagged SPY in 2023 and 2024 for the same reason. The total-return advantage in those years came from running a higher-vol structure on a stronger universe. The 2022 and 2025 regimes earned that volatility back.
What this actually bets on
The watchlist was not a momentum screen the agent ran for me. It is the watchlist I have been building over five years of running NexusTrade. NVDA, META, AVGO, and GOOG are on it because they are fundamentally strong, building out AI infrastructure, and have shown real positive momentum across the cycles I have tracked them through. You can cross-reference the same fundamental ratings I use in my stock reports page. I picked these names. The agent picked the structure to express them.
Be honest about what that means: the universe selection itself is doing most of the work. Buy-and-hold any of these four names over the last 16 months and you'd have crushed SPY too. The agent is not picking winning stocks. It's structuring trades on stocks I've already concluded are winners, with a macro filter that pulls to cash when SPY breaks its 200-day SMA, and per-name stops that close losers before they bleed. If you handed the same agent a watchlist of QSR, T, and PG, the regime numbers would not look like this.
If the thesis is wrong, this trade loses. That risk is mine, not the agent's. What the agent gets to handle is the part I am bad at: sizing, stops, and pulling out at the right moment. Which is why a watchdog runs every Monday and at every macro break.
Why in Public
The only honest test is the live tape.
I can argue that this works in a blog post all day. I can post backtests, regime sweeps, agent traces, watchdog logs. None of it matters until real money fills real orders and the P&L moves up or down on a public chart.
So here it is. The Public Portfolio Challenge. $25,000. Real money. Two spreads Tuesday morning, with NVDA in the wings if its filter clears at the open. A watchdog on call. Full agent traces. Full P&L visible.
If the platform works, the platform earns it. If it does not, you'll see the loss the same week I do.
I am terrified of failing publicly. I am also done waiting. The trade goes on Tuesday.
The Public Portfolio Challenge is open to anyone who wants to follow the P&L in real time. Every position. Every fill. Every loss.
Open the Live Portfolio →Build your own with Aurora → · Take the AI Agents from Scratch course →
No comments yet.