OpenAI is BACK in the AI race. A side-by-side comparison between DeepSeek R1 and OpenAI o3-mini
For the entire month of January, I’ve been an OpenAI hater.
I’ve repeatedly and publicly slammed them. I talked extensively about DeepSeek R1, their open-source competitor, and how a small team of Chinese researchers essentially destroyed OpenAI at their own game.
I also talked about Operator, their failed attempt at making a useful “AI agent” that can perform tasks fully autonomously.
So when Sam Altman declared that they were releasing o3-mini today, I thought it would be another failed attempt at stealing the thunder from actual successful AI companies.
I was 110% wrong. O3-mini is BEYOND amazing.
What is O3-mini?
OpenAI’s o3-mini is their new and improved Large Reasoning Model.
Unlike traditional large language models which respond instantly, reasoning models are designed to “think” about the answer before coming up with a solution. And this process used to take forever.
For example, when I integrated DeepSeek R1 into my algorithmic trading platform NexusTrade, I increased all of my timeouts to 30 minutes… for a single question.
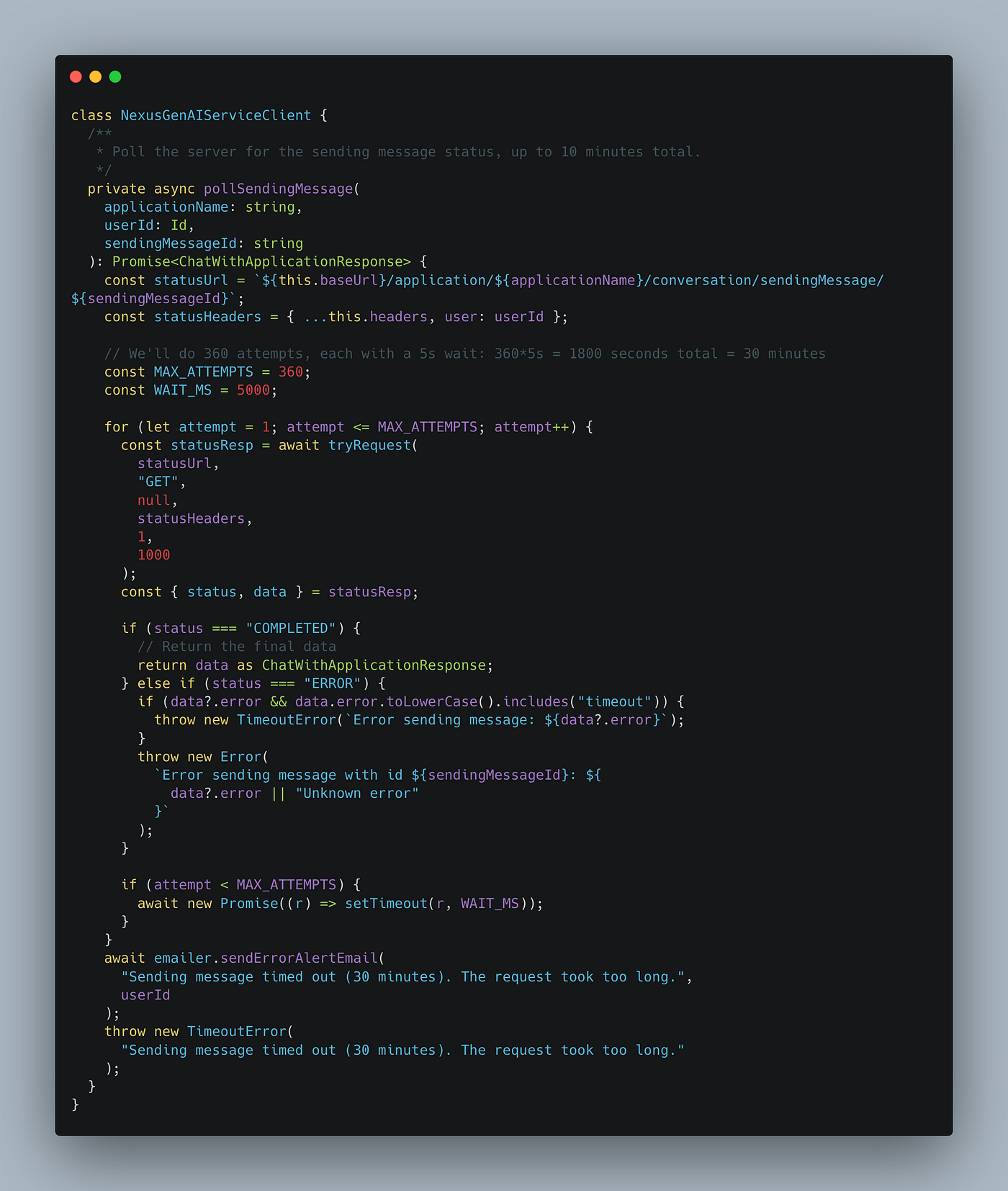
I also changed the implementation from a traditional request/response approach to a poll-based approach because the connection would simply timeout.
However, OpenAI did something incredible. Not only did they make a reasoning model that’s cheaper than their previous daily usage model, GPT-4o…

And not only is it simultaneously more powerful than their previous best model, O1…

BUT it’s also lightning fast. Much faster than any reasoning model that I’ve ever used by far.
And, when asked complex questions, it answers them perfectly, even better than o1, DeepSeek’s R1, and any other model I’ve ever used.
So, I thought to benchmark it. Let’s compare OpenAI’s o3 to the hottest language model of January, DeepSeek R1.
A side-by-side comparison of DeepSeek R1 and OpenAI o3-mini

We’re going to do a side-by-side comparison of these two models for one complex reasoning tasks: generating a complex, syntactically-valid SQL queries
We’re going to compare these models on the basis of:
- Accuracy: did the model generate the correct response?
- Latency: how long did the model take to generate its response?
- Cost: approximately, which model cost more to generate the response?
The first two categories are pretty self-explanatory. Here’s how we’ll compare the cost.
We know that DeepSeek R1 cost $0.75/M input tokens and $2.4/M output tokens.

In comparison, OpenAI’s o3 is $1.10/M input tokens and $4.4/M output tokens.

Thus, o3-mini is approximately 2x more expensive per request.
However, if the model generates an inaccurate query, there is automatic retry logic within the application layer.
Thus, to compute the costs, we’re going to see how many times the model retries, count the number of requests that are sent, and create an estimated cost metric. The baseline cost for R1 will be c, so at no retries, because o3-mini costs 2c (because it’s twice as expensive).
Now, let’s get started!
Using LLMs to generate a complex, syntactically-valid SQL query
We’re going to use an LLM to generate syntactically-valid SQL queries.
This task is extremely useful for real-world LLM applications. By converting plain English into a database query, we change our interface from buttons and mouse-clicks into something we can all understand – language.
How it works is:
- We take the user’s request and convert it to a database query
- We execute the query against the database
- We take the user’s request, the model’s response, and the results from the query, and ask an LLM to “grade” the response
- If the “grade” is above a certain threshold, we show the answer the the user. Otherwise, we throw an error and automatically retry.
Let’s start with R1
For this task, I’ll start with R1. I’ll ask R1 to show me strong dividend stocks. Here’s the request:
Show me large-cap stocks with:
- Dividend yield >3%
- 5 year dividend growth > 5%
- Debt/Equity <0.5
I asked the model to do this two separate times. In both tests, the model either timed out or didn’t find any stocks 🤦🏽
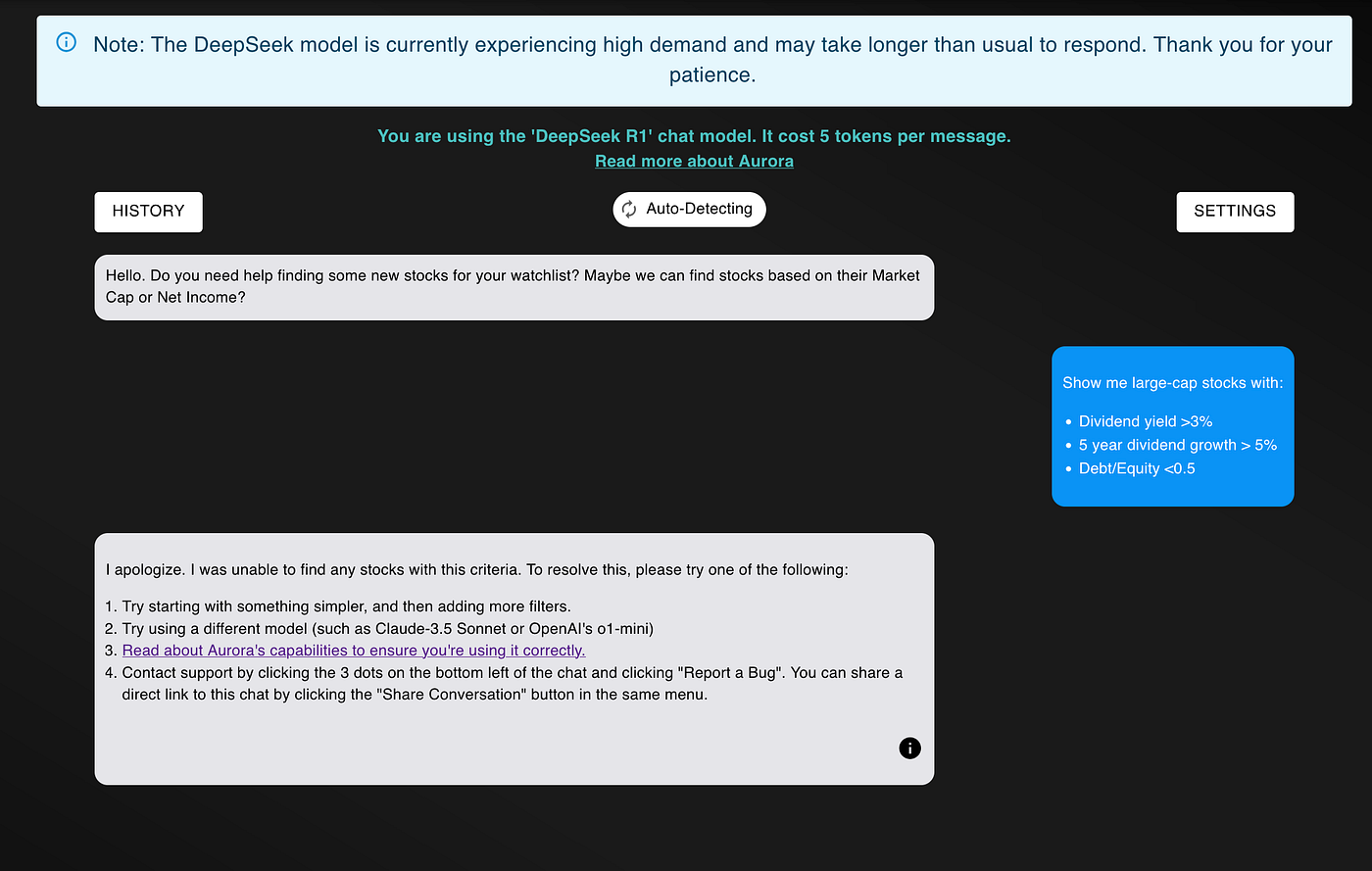
I swear to god that this isn’t cherry-picked.
When I dig deeper into the logs, I see that the model is struggling to generate an accurate query.
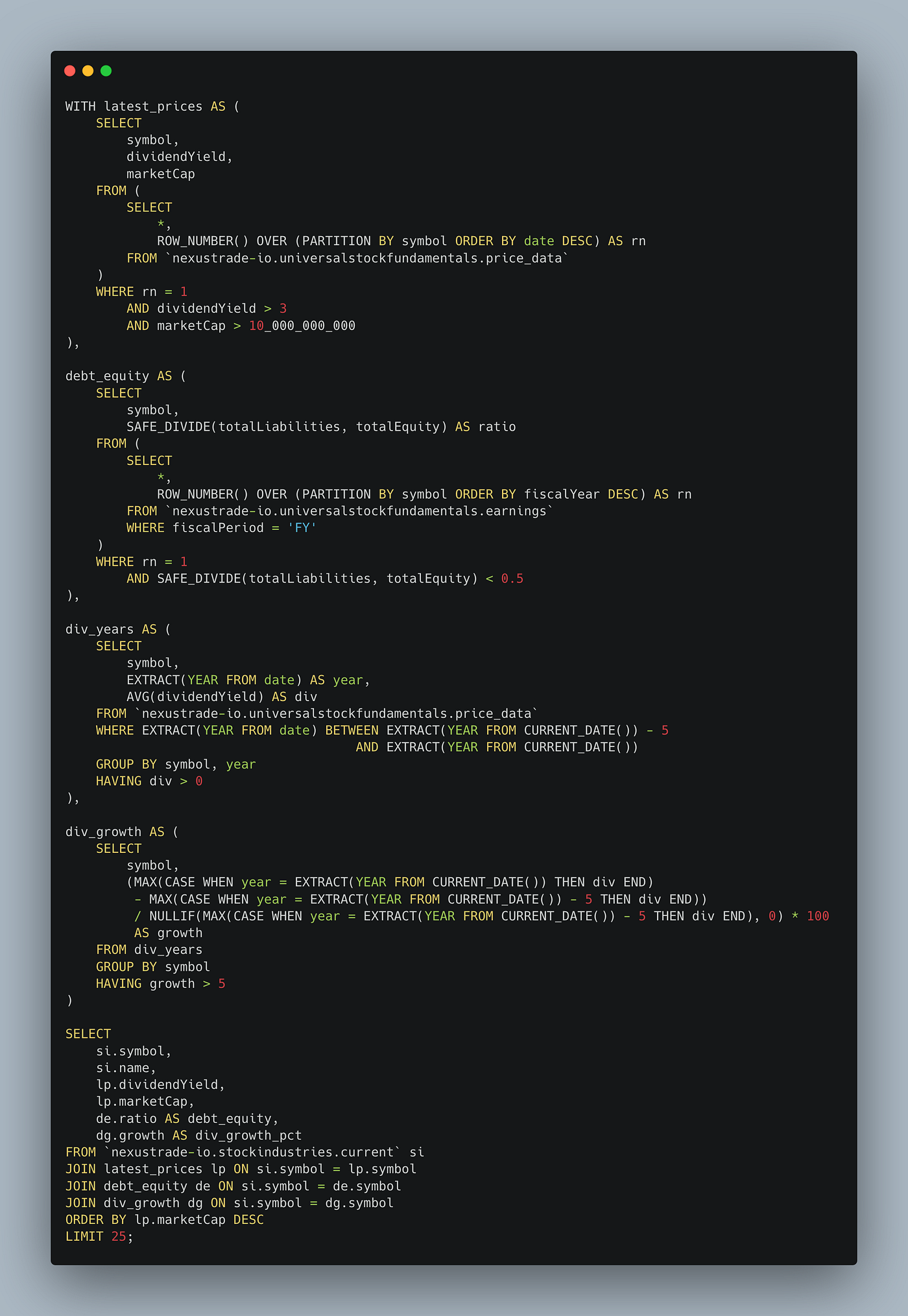
Just from manual inspection, we see that:
- It is using total liabilities, (not debt) for the ratio
- It’s attempting to query for the full year earnings, instead of using the latest quarter
- It’s using an average dividend yield for a trailing twelve month dividend figure
Finally, I had to check the db logs directly to see the amount of time elapsed.

These logs show that the model finally gave up after 41 minutes! That is insane! And obviously not suitable for real-time financial analysis.
Thus, for R1, the final score is
- Accuracy: it didn’t generate a correct response = 0
- Cost: with 5 retry attempts, it costs 5c + 1c = 6c
- Latency: 41 minutes
It’s not looking good for R1…
Now, let’s repeat this test with OpenAI’s new O3-mini model.
Next is O3
We’re going to ask the same exact question to O3-mini.
Unlike R1, the difference in speed was night and day.
I asked the question at 6:26PM and received a response 2 minutes and 24 seconds later.


This includes 1 retry attempt, one request to evaluate the query, and one request to summarize the results.
In the end, I got the following response.

We got a list of stocks that conform to our query. Stocks like Conoco, CME Group, EOG Resources, and DiamondBack Energy have seen massive dividend growth, have a very low debt-to-equity, and a large market cap.
If we click the “info” icon at the bottom of the message, we can also inspect the query.
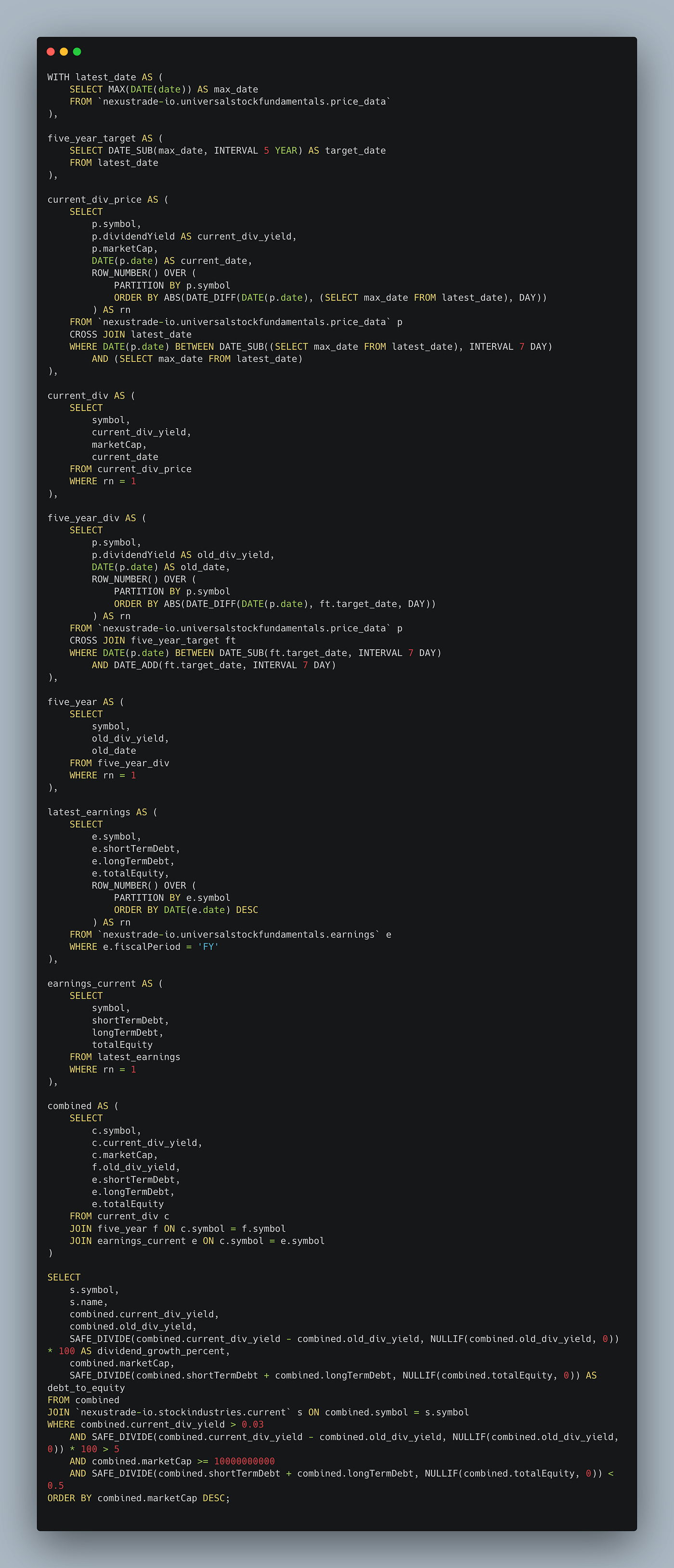
From manual inspection, we know that this query conforms to our request. Thus, for our final grade:
- Accuracy: it generated a correct response = 1
- Cost: 1 retry attempt + 1 evaluation query + 1 summarization query = 3c * 2 (because it’s twice as expensive) = 6c
- Latency: 2 minutes, 24 seconds
For this one example, we can see that o3-mini is better than r1 in every way. It’s many orders of magnitude faster, it costs the same, and it generated an accurate query to a complex financial analysis question.
To be able to do all of this for a price less than its last year daily-usage model is absolutely mindblowing.
Concluding Thoughts
After DeepSeek released R1, I admit that I gave OpenAI a lot of flak. From being extremely, unaffordably expensive to completely botching Operator, and releasing a slow, unusable toy masquerading as an AI agent, OpenAI has been taking many Ls in the month of January.
They made up for ALL of this with O3-mini.
This model put them back in the AI race at a staggering first place. O3-mini is lightning fast, extremely accurate, and cost effective. Like R1, I’ve integrated it for all users of my AI-Powered trading platform NexusTrade.
This release shows the exponential progress we’re making with AI. As time goes on, these models will continue to get better and better for a fraction of the cost.
And I’m extremely excited to see where this goes.
This analysis was performed with my free platform NexusTrade. With NexusTrade, you can perform comprehensive financial analysis and deploy algorithmic trading strategies with the click of a button.
Sign up today and see the difference O3 makes when it comes to making better investing decisions.
No comments yet.