I tested every AI Model on a complex SQL Query Generation Task. Here’s where Grok 4 stands
I spent $200 to test every language model. Here’s the best
Grok 4 dominated the benchmarks at its unveiling yesterday. In every single major benchmark, Grok 4 outpeformed even the best and heaviest reasoning models in every single task.
It’s honestly not even close.

These benchmarks are a decent proxy for general intelligence but they are not perfect. Popular benchmarks are easy to game and oftentimes unreliable for real-world tasks. So it got me thinking… how well does Grok 4 do on a real-world task?
I decided to test this objectively. Using a combination of Requesty and OpenRouter, platforms that allow aggregate LLMs into one API, I created a benchmark and spent over $200 testing each LLM on its SQL Query Performance.
Here’s what I found.
A Complex Benchmark NOT in the Training Data
To evaluate xAI’s new Grok 4 objectively, I’ve created a custom benchmark called EvaluateGPT.
EvaluateGPT allows me to test how well each new language model can generate accurate SQL queries for tough financial questions.

Think questions such as:
- “What AI stocks have the highest market cap?”
- “List companies with revenue growth of more than 20% year-over-year”
- “What are the top 10 stocks by revenue with a 2025 percent gain so far greater than its total 2024 percent gain? Sort by market cap descending”
And 85+ more.
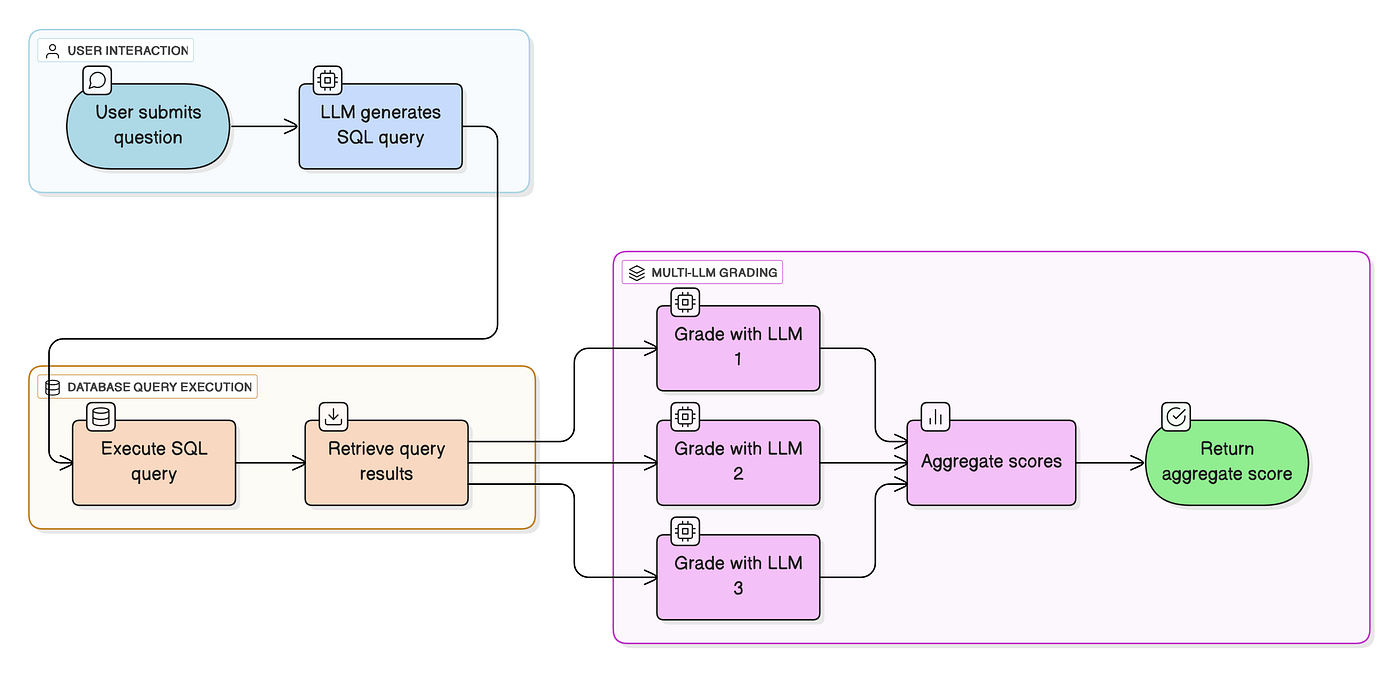
As Figure 4 suggests, the process for evaluating a model is as follows:
- A user submits a financial question to the model that we’re testing
- The LLM generates the SQL Query that can answer this question
- The SQL Query is executed against the database and fetch the results
- The Query and the results are fed into 3 powerful LLMs (Claude Sonnet 4, Gemini 2.5 Pro, and GPT-4.1) and they generate a score.
- The score is aggregated and we sort all of the models by their accuracy score
We then take the mean scores, median scores, and score distribution, an we create a table to compare each LLM to one another.
When I did this three months ago, I found that the Google models were among the most powerful for this particular task.
But three months is a long time in the AI space. I decided to re-run the entire experiment, and find out if Grok 4 was really as good as they want you to believe?
Spoiler alert: No, at least not for this task.
Grok 4, Claude 4, and Gemini 2.5 Pro. Which AI model is the best?

Based on the median and mean aggregate score in Figure 2, Google wins hands-down.
The table shows the performance of different LLMs across cost, speed, accuracy, and score distribution. It also has notes on each of the models. At first glance, we can see that:
- Gemini 2.5 Pro is the best model by far, scoring the highest median score and average score. Gemini 2.5 Flash is second best if you grade it according to its average score and input/output cost
- OpenAI’s o4-mini is second place in terms of raw median performance and output cost (which is very small compared to the input). The O3 model is 4th place, but worse in nearly every way
- Grok-4 trails behind, performing marginally better than Claude Sonnet 4 and GPT-4.1
- Claude Opus 4 is arguably the worst model on this list, being obscenely expensive, having low median performance, low average performance, and slow execution speeds.
Proving Google’s Dominance… Significantly
To verify these results, I wanted to test for statistical significance. To do this, I used OpenAI’s O3 model to help me perform a Repeated Measures One-Way ANOVA.
I ran a repeated-measures one-way ANOVA to verify if the differences between these models were actually meaningful (each of the 87 benchmark questions was answered by all 11 models). The results clearly backed up what Figure 2 suggested (F(10, 960) = 4.77, p < 0.001, partial η² ≈ 0.048). Post-hoc testing (Tukey HSD) confirmed that Google Gemini 2.5 Pro significantly outperformed all other models tested, while Grok 4 wasn’t statistically better than either Claude Sonnet 4 or GPT-4.1.
In simpler terms: the differences you’re seeing aren’t just random variation — Google’s lead is measurable, meaningful, and genuinely valuable when accuracy matters. Despite all of the chatter online, Google Gemini 2.5 Pro does best on this real-world, fair, complex reasoning task.
Why Does This Matter?
For one, these results demonstrate that benchmarks don’t show the full story.
Even though Grok 4 demolished every other model on the benchmark, it did not translate for my real-world reasoning task. This has a massive impact for my real-world app.
Why is it important for LLMs to generate accurate SQL Queries?
For context, I’m building NexusTrade, a platform to help investors create automated investing strategies and perform financial research.
One of the functionalities is configuring the model in the AI chat. Prior to this, I allowed 3 models: Gemini Flash 2, Gemini Flash 2.5, and Gemini 2.5 Pro.

These results show us that Gemini Flash 2.5 is significantly better than Gemini Flash 2 while only being slightly more expensive. The median one-shot accuracy increases from 0.567 to 0.900. This is an extremely significant difference!
However, to access this model, users had to pay 5x the “research tokens” within the app. This made this model completely inaccessible to free users. I decided that was unacceptable.
I removed Gemini Flash 2 from the model list and replaced it with Gemini Flash 2.5. As a result, my users will get a much better user experience at only a marginal increase in cost to me. This is insanely useful feedback. And it only cost me $200 to get it 😉.

How to take advantage of this?
If you’re an investor looking to make smarter investing decisions, NexusTrade is built with the most powerful LLMs to make it possible!
To start, NexusTrade’s financial analyses aren’t as simplistic as the benchmark. Each query goes through the following process.

- A user submits a financial question to the model that we’re testing
- The LLM generates the SQL Query that can answer this question
- The SQL Query is executed against the database and fetch the results
- The Query and the results are fed into the same model and we generate a score and a score explanation
- We repeat until the score is higher than our minimum score threshold
Because of this, NexusTrade can answer your financial questions with an extreme accuracy. If you’re trying to make smarter decisions in the market (which means earn more money in your pocket), NexusTrade gives you a clear path to do so.
Concluding Thoughts
With all of the hype around Grok 4, I would’ve expected an insane leap for this task.
Sadly, we didn’t get that.
These results show the Benchmark Fallacy in action. To summarize:
- According to the data, Grok 4 is a mediocre model for SQL Query generation, particularly for its price
- Google Gemini 2.5 Pro is cheaper (in terms of inputs and outputs), faster, and has a higher accuracy
- Even OpenAI’s o4-mini is a better model in nearly every regard.
Grok 4 simply doesn’t live up to the hype. At least in this task.
This article shows the importance of creating your own custom benchmarks. While I wasn’t able to justify adding Grok 4 into my algorithmic trading platform NexusTrade, I used the results of these benchmarks to improve the platform, making it far better with only a marginal increase in cost to myself. Users will now enjoy a much better more accurate experience.
What has your experience been with Grok 4? I’d love to hear how it performs on other tasks, whether its SQL Query Generation, coding, or any other real-world use-cases!
No comments yet.