I accidentally increased my backtesting speed by 99.9%. Here’s how.
100 Backtests in 300 Milliseconds. No, that’s not a typo.
Read the title, then read it again. If you’re like most people, you would assume I’m lying.
But I’m dead serious. I never sought to make a world-class backtesting engine. I wanted to fix a performance bug.
But now, a backtest that used to take me 45 seconds can be ran 400 times in under 1.2 seconds. The actual reduction is a staggering 99.89%. This is all thanks to Rust, a deep dive into performance engineering, and a vision for what AI can unlock when the underlying engine is fast enough.
Here’s exactly what I did.
Want to backtest your any trading idea that you can imagine in milliseconds without writing a single line of code? Create a free account on NexusTrade today!
What did I build before?
If you navigate to my Medium profile and scroll all the way down, you’ll notice my very first Medium article.
A no-code open-source trading platform
NextTrade was my first attempt at creating an algorithmic trading platform. And for a junior engineer writing code before the days of LLMs, it’s honestly not too bad.
The system implements surprisingly powerful no-code algorithmic trading logic Using this, a semi-technical trader can create custom indicators, then configure their trading logic in a UI. But it came with a cost.
As slow as a salted snail in the Sahara
NexusTrade was slow, like really slow. Take a strategy like this for example.
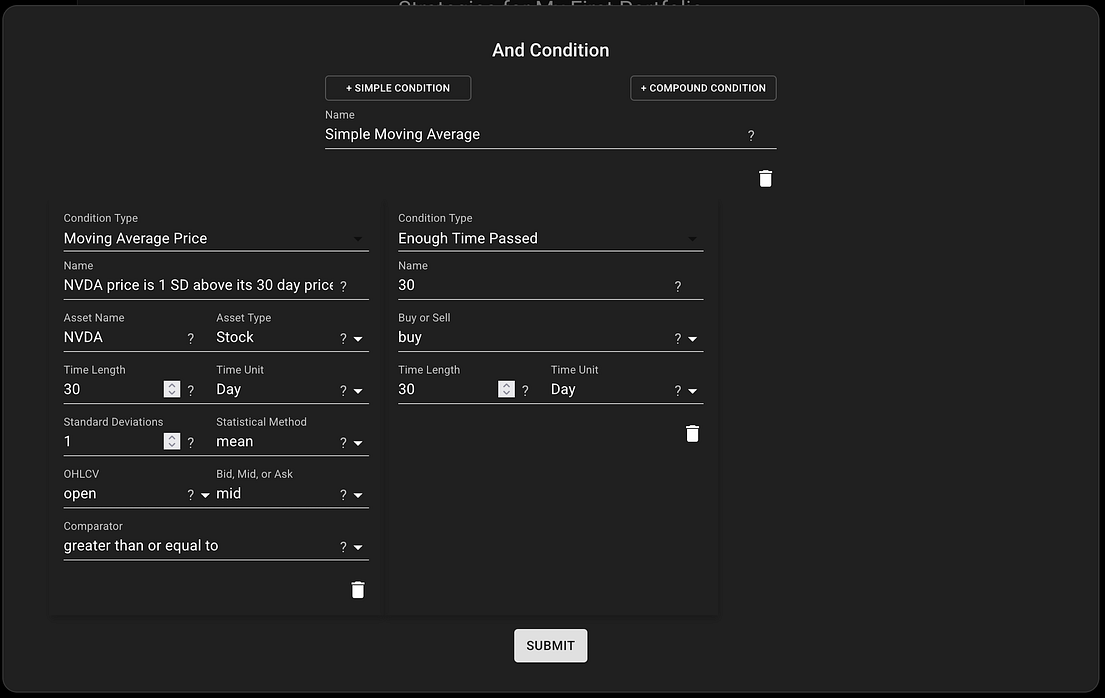
This is a simple condition that is considered “true” if NVDA’s price is 1 standard deviation above its 30 day average price and 30 days passed since the last buy.
In NextTrade, computing these conditions was expensive. The process is as naive as a Catholic schoolgirl at her first frat party. At every single time interval, we would:
- Fetch the stock’s 30 day price
- Sum the array and divide by the length to compute the mean
- Compute the sum of squared differences to compute the variance
- Take the standard deviation and compare the result to the asset’s price
- Iterate over all past orders and find the one that was 30 or more days away
Repeat this for every single day.
This was slow with just one indicator; imagine if your strategy had 100.
I decided to see approximately how slow this simple was. Using a Macbook M3 Pro Max with 128GB of RAM and 11 CPUs, a simple backtest from January 1st, 2010 to September 8th, 2025 took 45,399 milliseconds.
45 seconds for possibly the world’s simplest strategy.
Moreover, there were other issues, such as the lack of configurability, that also made NextTrade impossible to scale as a real application. Because of this, I open-sourced it and went back to the drawing board.
Falling for Reddit’s propaganda, I decided to do a full rewrite in Rust and experienced a Six-Flags-esque whirlwind of emotions with it.
What I’ve Built Since: The No-Code NexusTrade Engine
After releasing NextTrade, I started a complete rewrite of my application. The result is NexusTrade, an AI-integrated trading platform that now gives QuantConnect and other institutional platforms a run for their money.
Using NexusTrade, a trader can create, backtest, optimize, and deploy their trading strategies using natural language. This is immensely easier than writing Pinescript for TradingView or coding ideas in C# for QuantConnect.
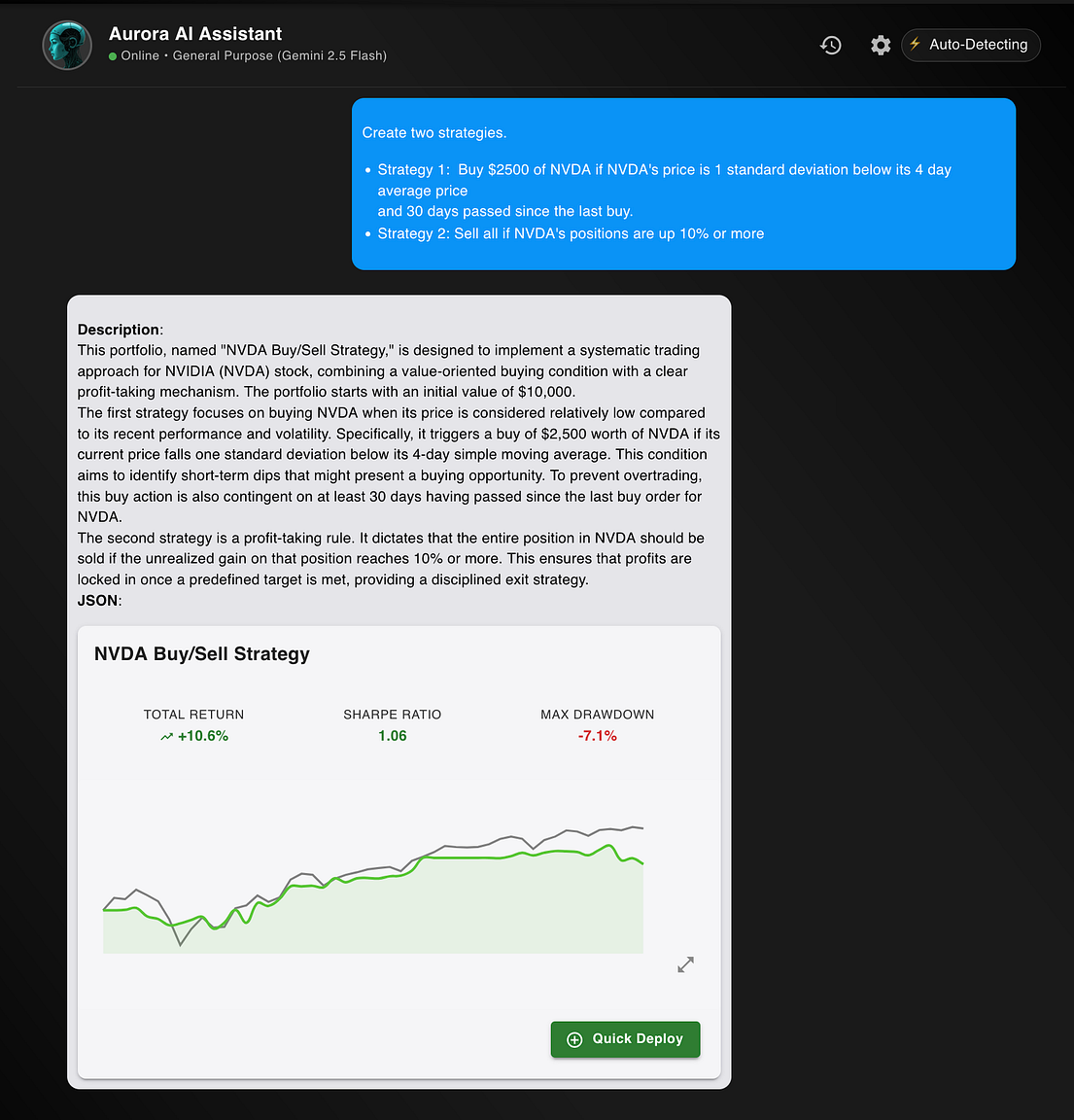
With these new improvements, I strongly believe in my heart-of-hearts that NexusTrade is the best algorithmic trading platform for retail investors.
But the journey here wasn't easy.
When I started this initiative, I didn’t know Rust at all and didn’t realize I was entering into a swimming pool of angry crabs that would fight me anytime I tried to write a single line of code.
I hated it.
I struggled hard and eventually just aimed to write code that just compiled. This meant asyncs everywhere (even for functions that didn’t need it), expensive cloning, and bad memory patterns (such as loading a backtest’s entire historical data into memory for each request).
And even with this, the performance gains were immense. While the simple backtest from above took 45 seconds in TypeScript; a far more complex one, involving complex rebalancing logic on a set of assets, took around 22 seconds in Rust. That’s a 50%+ improvement with the switch alone.
This immediately unlocked other use-cases, like performing advanced arithmetic using fundamental indicators from APIs like EODHD. I could now perform backtests not just with price data, but historical fundamentals as well.
But the real gains weren’t from the refactor. It was from intense performance engineering thanks to the power of Claude Opus 4.1 and Gemini 2.5 Pro.
Here’s what I did, step-by-step.
Want high-quality fundamental data for your application? Create a free account on EODHD today!
How I optimized NexusTrade to an Institutional-Grade level
Funny enough, my goal was never to make NexusTrade faster. In my eyes, the backtesting was fast enough.
My goal was to solve an unrelated issue – memory bottlenecks.
The Bottleneck of a Poor Design
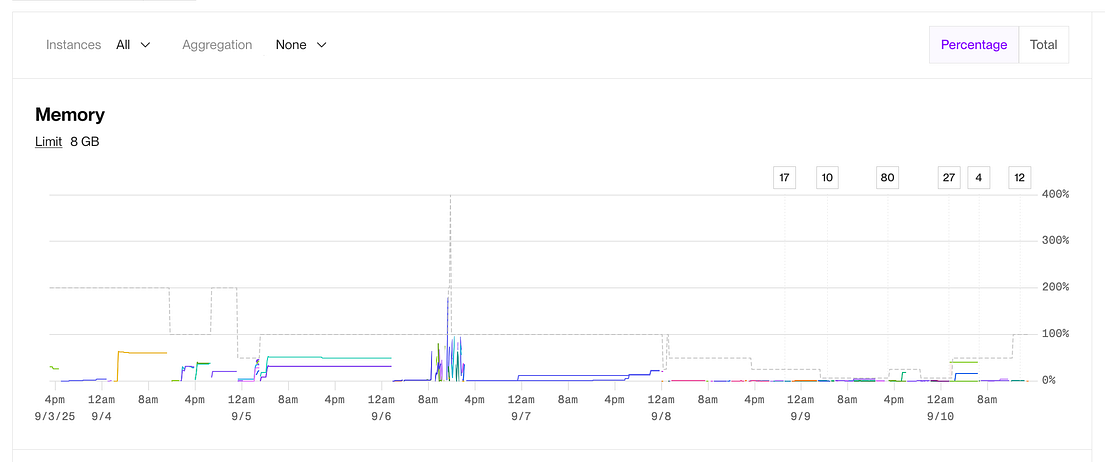
Typically, memory for my application was stable. But if someone hopped on the app and started running a dozen backtests, this caused issues, particularly if the data size was large.
The app would become stuck in a crash loop. To resolve it, I’d temporarily upgrade my instance to the whopping $450/month Pro Ultra plan, wait for the backtests to finish, then scale it back down.
I sought to truly fix this.
At this point, I hardly touched the Rust code after the initial re-write. Sure, I might extend the indicator class or pipe in fundamental data from MongoDB. But I didn’t dare to touch anything else.
But now we have AI.
How I used AI to solve my memory bottleneck (and uncover new issues)
I copy-pasted my full backtesting code into Claude and Gemini. I described my memory bottleneck problems and asked for solutions.
The results were insane.
I used these models to create a bulletproof plan. My workflow was as follows:
- I’d generate a plan using one of the AI models
- I’d copy/paste the plan into the other model and asked it to critique it.
- I’d copy/paste the critique into the original model and asked for criticism and feedback. I’d also give my own opinion, and supplied architectural knowledge of my codebase when needed
- I’d repeat until the plan was flawless
Each model came up with different solutions. One model might’ve suggested streaming the data instead of loading it into memory. Another might’ve suggested passing in an iterator with batches of market data.
After a while, I eventually arrived at an architecture that I had never heard of before – memory maps (mmap).
A memory-mapped file (mmap) is a way for programs to treat the contents of a file as if it were directly in memory (RAM).
Instead of reading and writing a file through normal system calls (which involve copying data between kernel space and user space), the operating system maps the file into the process’s virtual address space. From the program’s perspective, it looks like a block of memory, but behind the scenes, the OS loads pages of the file into RAM as needed.
I had no idea what this was and even less of an idea of how to implement it. So I used the same back-and-forth process to create a detailed implementation plan.
I then fed this plan into Claude Code, and told it to look for all of the related code in my codebase and create a new plan. I then told it to implement it.
I want to stress that this was not “vibe-coding”. I watched it meticulously, pasted foreign unknown code into Gemini to help me understand, and learned a new concept on the fly. I then used AI models to code review every single line that was produced. Once, I even had to revert a full day of work because I couldn’t solve a corrupted memory issue with my implementation.
(It had to deal with padding).
But thanks to my extensive suite of regression tests, I eventually I got to the finish line and migrated successfully to mmaps. However, there was still one HUGE issue.
The simulation was now twice as slow.
How I used AI to make my backtest lightning fast
Accepting that my code would just be slower was not an option. Using the same methodology as before, I repeated this process for debugging why my code was slow.
I eventually learned that my code structure had serious issues and that I needed a complete architectural revamp. I removed async code, eliminated control flow by errors, and replaced expensive clones when possible.
Little by little, my program became faster, eventually matching and exceeding the performance before the refactor!
But at this point, I became greedy. How much faster can it really be?
I wanted more.
How I achieved sub-second backtesting performance
When we exhausted the obvious quick-wins, the models told me to use flamegraph to visualize where my code was spending most of its time. Not being able to decipher what the profile visualizations meant, I gave it to the AI models.
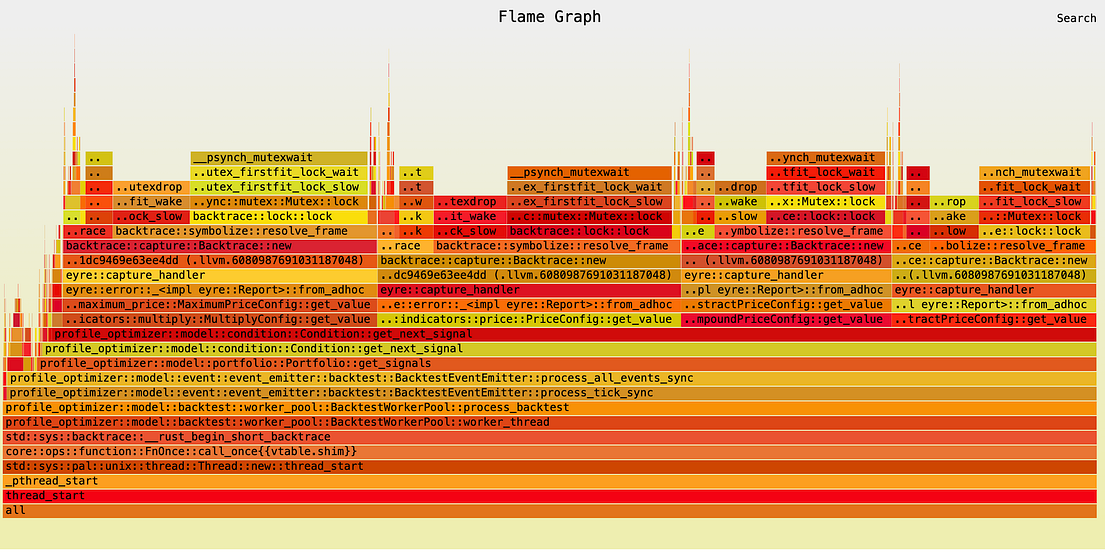
From here, the progress was exponential. To make a long(er) story short, my system improved dramatically in every single way.
Some of the biggest bottlenecks were things I would have never thought of, such as
- Using errors as control flow, combined with generating massive stack-traces using color_eyre
- Improper parallelization using block_on
- Cloning large objects, particularly in tight loops
- I/O bottlenecks due to poor batching, small buffers, and the lack of data projections
I fixed these issues systematically. I introduced channels for things like progress saving and real-time updates. I eliminated async when it wasn’t needed, and parallelized CPU-intensive tasks using rayon.
I kept going until every single LLM unanimously agreed that I created the perfect solution. I then ran a final benchmark and threw my laptop against the wall.
The results were almost comical.
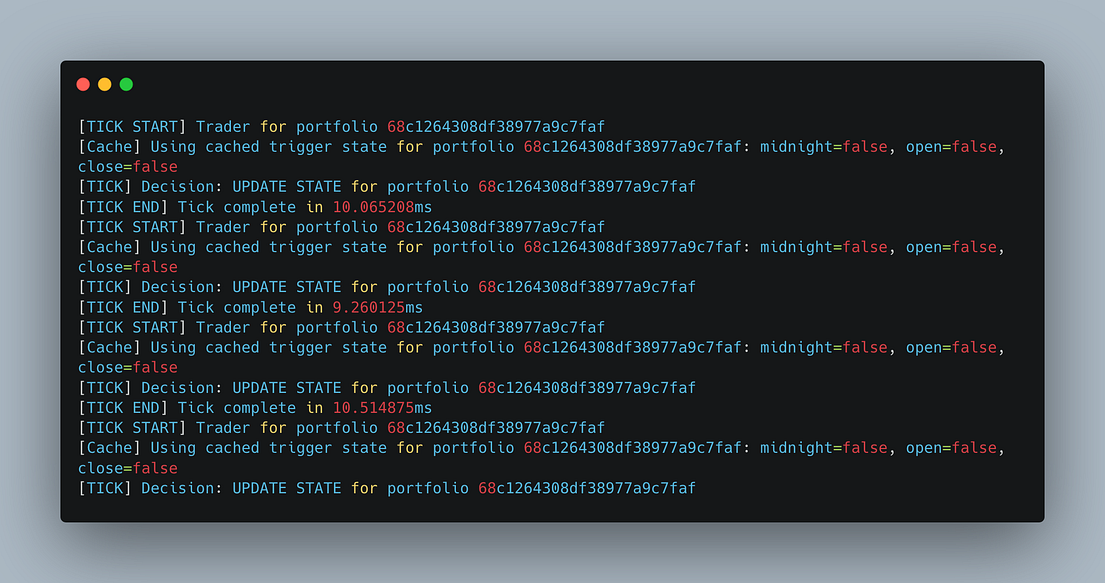
To truly test the new engine’s capabilities, I created an insanely complicated portfolio. This wasn’t just a simple simple moving average strategy on one stock; it was a large genetic optimization of a 100-asset rebalancing strategy that made daily decisions based on both price data and intricate, point-in-time fundamental data lookups for each asset. It demanded the highest computational throughput and data handling efficiency.
Optimizing my portfolio using genetic optimization, I measured something incredible. An entire generation of 300 full backtests, simulating nearly two years of this complex strategy for each trading day, completed in an astonishing 87.5 seconds. That means each individual, fundamentally-driven, 100-asset backtest took just 292 milliseconds.
With the old system, this would’ve taken hours, if not days to complete, while completely blocking the runtime and preventing other work from being done.
But the gains don’t stop there.
I applied this performance optimization process to my web app and live-trading service. For example, I refactored my stateless live-trader to a stateful system with optimistic concurrency, saving on substantial CPU and memory.
Not only did I build a better, faster, and more resilient algorithmic trading system, but I also saved an insane amount of money as a side effect.
Bonus Points: How Rust saved me 60% on compute costs

The performance gains didn’t just make the system faster — they slashed my infrastructure costs to a tiny fraction.
- Live trading service: $225/month → $7/month (97% reduction)
- Backtesting engine: $225/month → $85/month (62% reduction)
- Workers: $85/month (unchanged)
- Web servers: $170/month → $100/month (41% reduction)
My monthly infrastructure bill plummeted from $705 to $277. That’s a 60.7% reduction in compute costs for free. This not given my platform institutional-grade performance, but it secretly unlocked new use-cases that I previously couldn’t imagine.
A Limitless Possibility of New Exciting Use Cases
These improvements have unlocked a future of endless possibilities. For example, genetic optimization, which used to be so computationally expensive that I had to restrict it to premium tiers, is now so blazingly fast that I can afford to offer it to every single NexusTrade user for free.
I’ve also added new high-priority features to the roadmap, that will benefit everybody. My first order of business is to integrate the genetic optimizer directly into the AI chat. Users will be able to optimize their strategy parameters by literally asking an AI to do it… and the process will just take several seconds.
Additionally, I can add this optimizer to Aurora’s toolkit. Aurora is the AI Agent that can autonomously generate new trading ideas with no human intervention required.
Finally, the memory-mapped file architecture that solved my memory bottleneck also enabled two previously impossible use cases: intraday backtesting and real-time (sub-second) trading simulation.
If I can run backtests on years of data in milliseconds, what excuse do I have for not testing every single trading idea that crosses my mind?
The possibilities are endless.
Concluding Thoughts
Let me beperfectly clear – this performance improvement was a mistake. My goal was to reduce the memory of my Rust app to prevent crashes. The end result is possibly the best, fastest, most powerful retail-facing trading platform the world has ever seen.
The journey here wasn’t easy. When I started using Rust, I hated it. I fought the compiler at every second, cursed the borrow-checker, and spammed the async keyword like it was free.
But thanks to language models, using Rust couldn’t be easier. I used AI to generate an implementation plan, juggled the plan between different models, and made it bulletproof. I eliminated I/O bottlenecks, paralleized computation, and truly unlocked the power that Rust promises.
I see what the Rustaceons mean now.

This is a seismic shift in the world of retail trading. If you’re an ordinary person and you want to test your trading ideas on years of data the ability to code your trading ideas is no longer a barrier.
You just have to articulate them, in plain English, and let AI and the power of Rust do the rest.
Want to see how fast it is yourself? Create a free account on NexusTrade and experience the power of lightning-fast, AI-enabled algorithmic trading.
No comments yet.